これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
クラスターの管理
- 1: kubeadmによる管理
- 1.1: Linuxワーカーノードの追加
- 1.2: cgroupドライバーの設定
- 1.3: kubeadmクラスターのアップグレード
- 1.4: Windowsノードの追加
- 1.5: Windowsノードのアップグレード
- 1.6: kubeadmによる証明書管理
- 2: dockershimからの移行
- 2.1: ノードのコンテナランタイムをDocker Engineからcontainerdに変更する
- 2.2: ノードで使用されているコンテナランタイムの確認
- 2.3: dockershim削除の影響範囲を確認する
- 2.4: dockershimからテレメトリーやセキュリティエージェントを移行する
- 3: 証明書を手動で生成する
- 4: メモリー、CPU、APIリソースの管理
- 5: 拡張リソースをNodeにアドバタイズする
- 6: クラウドコントローラーマネージャーの運用管理
- 7: kubelet image credential providerの設定
- 8: ノードのトポロジー管理ポリシーを制御する
- 9: ネットワークポリシーを宣言する
- 10: クラウドコントローラーマネージャーの開発
- 11: Kubernetes向けetcdクラスターの運用
- 12: ノードを安全にドレインする
- 13: クラスターのセキュリティ
- 14: クラスターのアップグレード
- 15: クラスターでカスケード削除を使用する
- 16: データ暗号化にKMSプロバイダーを使用する
- 17: サービスディスカバリーにCoreDNSを使用する
- 18: KubernetesクラスターでNodeLocal DNSキャッシュを使用する
- 19: EndpointSliceの有効化
1 - kubeadmによる管理
1.1 - Linuxワーカーノードの追加
このページでは、kubeadmクラスターにLinuxワーカーノードを追加する方法を示します。
始める前に
- ワーカーノードとして追加する各マシンに、kubeadmのインストールで要求されている、kubeadm、kubelet、コンテナランタイム等のコンポーネントがインストールされていること。
kubeadm initで構築され、kubeadmを使用したクラスターの作成ドキュメントの手順に従った稼働中のkubeadmクラスターが存在すること。- ノードにスーパーユーザー権限でアクセスできること。
Linuxワーカーノードの追加
新たなLinuxワーカーノードをクラスターに追加するために、以下を各マシンに対して実行してください。
- SSH等の手段でマシンへ接続します。
kubeadm init実行時に出力されたコマンドを実行します。例:
sudo kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
kubeadm joinに関する追加情報
備考:
<control-plane-host>:<control-plane-port>にIPv6タプルを指定するには、IPv6アドレスを角括弧で囲みます。
例: [2001:db8::101]:2073トークンが不明な場合は、コントロールプレーンノードで次のコマンドを実行すると取得できます。
# コントロールプレーンノード上で実行してください。
sudo kubeadm token list
出力は次のようになります。
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
デフォルトでは、トークンは24時間後に有効期限が切れます。 現在のトークンの有効期限が切れた後にクラスターにノードを参加させたい場合は、コントロールプレーンノード上で次のコマンドを実行することで、新しいトークンを生成できます。
# コントロールプレーンノード上で実行してください。
sudo kubeadm token create
このコマンドの出力は次のようになります。
5didvk.d09sbcov8ph2amjw
新たなトークンを生成しながらkubeadm joinコマンドを出力するには、次のコマンドを使用します。
sudo kubeadm token create --print-join-command
--discovery-token-ca-cert-hashの値が不明な場合は、コントロールプレーンノード上で次のコマンドを実行することで取得できます。
# コントロールプレーンノード上で実行してください。
sudo cat /etc/kubernetes/pki/ca.crt | openssl x509 -pubkey | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
出力は次のようになります。
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
kubeadm joinコマンドによって以下のように出力されるはずです。
[preflight] Running pre-flight checks
... (log output of join workflow) ...
Node join complete:
* Certificate signing request sent to control-plane and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on control-plane to see this machine join.
数秒後、kubectl get nodesを実行すると、出力内にこのノードが表示されるはずです(kubectlコマンドは、コントロールプレーンノード等で実行してください)。
備考:
クラスターのノードは、通常は順番に初期化されるため、CoreDNSのPodは全て最初のコントロールプレーンノードで実行されている可能性があります。 高可用性を実現するため、新たなノードを追加した後にはkubectl -n kube-system rollout restart deployment corednsコマンドを実行してCoreDNSのPodを再配置してください。次の項目
- Windowsワーカーノードを追加する方法を参照してください。
1.2 - cgroupドライバーの設定
このページでは、kubeadmクラスターのコンテナランタイムcgroupドライバーに合わせて、kubelet cgroupドライバーを設定する方法について説明します。
始める前に
Kubernetesのコンテナランタイムの要件を熟知している必要があります。
コンテナランタイムのcgroupドライバーの設定
コンテナランタイムページでは、kubeadmベースのセットアップではcgroupfsドライバーではなく、systemdドライバーが推奨されると説明されています。
このページでは、デフォルトのsystemdドライバーを使用して多くの異なるコンテナランタイムをセットアップする方法についての詳細も説明されています。
kubelet cgroupドライバーの設定
kubeadmでは、kubeadm initの際にKubeletConfiguration構造体を渡すことができます。
このKubeletConfigurationには、kubeletのcgroupドライバーを制御するcgroupDriverフィールドを含めることができます。
備考:
v1.22では、ユーザーがKubeletConfigurationのcgroupDriverフィールドを設定していない場合、kubeadmはデフォルトでsystemdを設定するようになりました。フィールドを明示的に設定する最小限の例です:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
このような設定ファイルは、kubeadmコマンドに渡すことができます:
kubeadm init --config kubeadm-config.yaml
備考:
Kubeadmはクラスター内の全ノードで同じKubeletConfigurationを使用します。
KubeletConfigurationはkube-system名前空間下のConfigMapオブジェクトに格納されます。
サブコマンドinit、join、upgradeを実行すると、kubeadmがKubeletConfigurationを/var/lib/kubelet/config.yaml以下にファイルとして書き込み、ローカルノードのkubeletに渡します。
cgroupfsドライバーの使用
このガイドで説明するように、cgroupfsドライバーをkubeadmと一緒に使用することは推奨されません。
cgroupfsを使い続け、kubeadm upgradeが既存のセットアップでKubeletConfiguration cgroupドライバーを変更しないようにするには、その値を明示的に指定する必要があります。
これは、将来のバージョンのkubeadmにsystemdドライバーをデフォルトで適用させたくない場合に適用されます。
値を明示する方法については、後述の「kubelet ConfigMapの修正」の項を参照してください。
cgroupfsドライバーを使用するようにコンテナランタイムを設定したい場合は、選択したコンテナランタイムのドキュメントを参照する必要があります。
systemdドライバーへの移行
既存のkubeadmクラスターのcgroupドライバーをsystemdにインプレースで変更する場合は、kubeletのアップグレードと同様の手順が必要です。
これには、以下に示す両方の手順を含める必要があります。
備考:
あるいは、クラスター内の古いノードをsystemdドライバーを使用する新しいノードに置き換えることも可能です。
この場合、新しいノードに参加する前に以下の最初のステップのみを実行し、古いノードを削除する前にワークロードが新しいノードに安全に移動できることを確認する必要があります。kubelet ConfigMapの修正
kubectl get cm -n kube-system | grep kubelet-configで、kubelet ConfigMapの名前を探します。kubectl edit cm kubelet-config-x.yy -n kube-systemを呼び出します(x.yyはKubernetesのバージョンに置き換えてください)。- 既存の
cgroupDriverの値を修正するか、以下のような新しいフィールドを追加します。
cgroupDriver: systemd
このフィールドは、ConfigMapのkubelet:セクションの下に存在する必要があります。
全ノードでcgroupドライバーを更新
クラスター内の各ノードについて:
- Drain the nodeを
kubectl drain <node-name> --ignore-daemonsetsを使ってドレーンします。 systemctl stop kubeletを使用して、kubeletを停止します。- コンテナランタイムの停止。
- コンテナランタイムのcgroupドライバーを
systemdに変更します。 var/lib/kubelet/config.yamlにcgroupDriver: systemdを設定します。- コンテナランタイムの開始。
systemctl start kubeletでkubeletを起動します。- Drain the nodeを
kubectl uncordon <node-name>を使って行います。
ワークロードが異なるノードでスケジュールするための十分な時間を確保するために、これらのステップを1つずつノード上で実行します。 プロセスが完了したら、すべてのノードとワークロードが健全であることを確認します。
1.3 - kubeadmクラスターのアップグレード
このページでは、kubeadmで作成したKubernetesクラスターをバージョン1.33.xから1.34.xに、または1.34.xから1.34.y (y > x)にアップグレードする方法を説明します。マイナーバージョンを飛ばしてのアップグレードはサポートされていません。詳細はVersion Skew Policyを参照してください。
古いバージョンのkubeadmで作成したクラスターのアップグレードについては、次のページを参照してください。
- 1.33から1.34へのkubeadmクラスターのアップグレード
- 1.32から1.33へのkubeadmクラスターのアップグレード
- 1.31から1.32へのkubeadmクラスターのアップグレード
- 1.30から1.31へのkubeadmクラスターのアップグレード
Kubernetesプロジェクトでは最新のパッチリリースへの早めのアップグレードと、サポート対象のマイナーリリースを実行することを推奨しています。これによりセキュリティを維持できます。
アップグレードの大まかなワークフローは次の通りです。
- プライマリコントロールプレーンノードをアップグレードする。
- 追加のコントロールプレーンノードをアップグレードする。
- ワーカーノードをアップグレードする。
前提条件
- リリースノートをよく確認してください。
- クラスターは静的コントロールプレーンとetcd Pod、または外部etcdを使用している必要があります。
- データベースに保存されたアプリケーションレベルの状態など、重要なコンポーネントのバックアップを取ってください。
kubeadm upgradeはワークロードには触れず、Kubernetes内部のコンポーネントのみを対象としますが、バックアップは常に推奨されます。 - Swapを無効にする必要があります。
追加情報
- 以下の手順は、アップグレード中にいつノードをドレインするかの目安を示しています。kubeletのマイナーバージョンアップグレードを行う場合、対象ノードは事前にドレインする必要があります。コントロールプレーンノードの場合、CoreDNS Podや他の重要なワークロードが実行されている可能性があります。詳しくはノードのドレインを参照してください。
- Kubernetesプロジェクトではkubeletとkubeadmのバージョンを合わせることを推奨しています。kubeadmより古いkubeletを使うことは可能ですが、サポートされているバージョン範囲内である必要があります。詳細はkubeletに対するkubeadmのバージョンの差異を参照してください。
- アップグレード後はすべてのコンテナが再起動されます。これはコンテナのハッシュ値が変わるためです。
- kubeletのアップグレード後にkubeletサービスが正常に再起動したことを確認するには、
systemctl status kubeletを実行するか、journalctl -xeu kubeletでサービスログを確認できます。 kubeadm upgradeは--configフラグでUpgradeConfigurationAPI typeを受け付けます。これによりアップグレードプロセスを構成できます。kubeadm upgradeは既存クラスターの再構成をサポートしません。既存クラスターの再構成についてはReconfiguring a kubeadm clusterの手順に従ってください。
etcdのアップグレードに関する考慮事項
kube-apiserverのStatic Podは(ノードをドレインしていても)常に実行されているため、etcdのアップグレードを含むkubeadmアップグレードを実行すると、新しいetcd Static Podが再起動している間にサーバーへの処理中のリクエストが停滞する可能性があります。回避策として、kubeadm upgrade applyコマンドを開始する数秒前にkube-apiserverプロセスを一時的に停止することが可能です。こうすることで処理中のリクエストを完了させ、既存接続をクローズでき、etcdのダウンタイムの影響を最小限にできます。コントロールプレーンノードでは次のように行います。
killall -s SIGTERM kube-apiserver # kube-apiserverのグレースフルシャットダウンをトリガーする
sleep 20 # 処理中のリクエストの完了まで少し待つ
kubeadm upgrade ... # kubeadm upgradeコマンドを実行
パッケージリポジトリの変更
- コミュニティが運営するパッケージリポジトリ(
pkgs.k8s.io)を使用している場合、目的のKubernetesマイナーリリース向けにパッケージリポジトリを有効にする必要があります。詳しくはChanging The Kubernetes Package Repositoryを参照してください。
apt.kubernetes.io and yum.kubernetes.io) have been
deprecated and frozen starting from September 13, 2023.
Using the new package repositories hosted at pkgs.k8s.io
is strongly recommended and required in order to install Kubernetes versions released after September 13, 2023.
The deprecated legacy repositories, and their contents, might be removed at any time in the future and without
a further notice period. The new package repositories provide downloads for Kubernetes versions starting with v1.24.0.
アップグレード先バージョンを決定する
OSのパッケージマネージャーを使って、Kubernetes 1.34の最新パッチを見つけます。
# リスト内の最新の1.34バージョンを探します。
# 形式は1.34.x-*のようになります。
sudo apt update
sudo apt-cache madison kubeadm
DNFを使うシステム:
# リスト内の最新の1.34バージョンを探します。
# 形式は1.34.x-*のようになります。
sudo yum list --showduplicates kubeadm --disableexcludes=kubernetes
DNF5を使うシステム:
# リスト内の最新の1.34バージョンを探します。
# 形式は1.34.x-*のようになります。
sudo yum list --showduplicates kubeadm --setopt=disable_excludes=kubernetes
期待するバージョンが表示されない場合は、Kubernetesパッケージリポジトリが利用されているか確認してください
コントロールプレーンノードのアップグレード
コントロールプレーンノードのアップグレードはノードごとに順に実行する必要があります。まずアップグレードするコントロールプレーンノードを選んでください。そのノードには/etc/kubernetes/admin.confファイルが存在する必要があります。
kubeadm upgradeの実行
最初のコントロールプレーンノードの場合
-
kubeadmをアップグレードします。
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.34.x-*' && \ sudo apt-mark hold kubeadmDNFを使うシステム:
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo yum install -y kubeadm-'1.34.x-*' --disableexcludes=kubernetesDNF5を使うシステム:
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo yum install -y kubeadm-'1.34.x-*' --setopt=disable_excludes=kubernetes -
ダウンロードが期待したバージョンであることを確認します。
kubeadm version -
アップグレードプランを確認します。
sudo kubeadm upgrade planこのコマンドはクラスターがアップグレード可能かどうかをチェックし、アップグレードできるバージョンを取得します。また、コンポーネント設定のバージョン状態を示すテーブルも表示します。
備考:
kubeadm upgradeはこのノードで管理している証明書の更新も自動で行います。証明書更新を無効にするには--certificate-renewal=falseフラグを使用できます。証明書管理の詳細はkubeadmによる証明書管理を参照してください。 -
アップグレードするバージョンを選び、適切なコマンドを実行します。例えば:
# 今回選んだパッチバージョンでxを置き換えてください sudo kubeadm upgrade apply v1.34.xコマンドが終了すると、次のようなメッセージが表示されます。
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.34.x". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.備考:
v1.28より前のバージョンでは、kubeadmは他のコントロールプレーンインスタンスがアップグレードされていない場合でも、kubeadm upgrade apply実行中にアドオン(CoreDNSやkube-proxyを含む)を直ちにアップグレードするモードがデフォルトでした。これは互換性の問題を引き起こす可能性があります。v1.28以降、kubeadmは全てのコントロールプレーンインスタンスがアップグレードされているかを確認してからアドオンのアップグレードを開始するモードをデフォルトにしています。コントロールプレーンインスタンスは順次アップグレードするか、最後のインスタンスのアップグレードを他のインスタンスの完了まで開始しないようにしてください。アドオンのアップグレードは最後のコントロールプレーンインスタンスがアップグレードされた後に行われます。 -
CNIプロバイダーのプラグインを手動でアップグレードします。
コンテナネットワークインターフェース(CNI)プロバイダーはそれ自体のアップグレード手順を持つ場合があります。アドオンのページで使用しているCNIプロバイダーを確認し、追加のアップグレード手順が必要かどうかを確認してください。
なお、CNIプラグインがDaemonSetで動作している場合、追加のコントロールプレーンノードではこの手順は不要です。
他のコントロールプレーンノードの場合
最初のコントロールプレーンノードと同様の手順ですが、
sudo kubeadm upgrade apply
の代わりに、
sudo kubeadm upgrade node
を使用します。
また、kubeadm upgrade planの実行やCNIプラグインのアップグレードは不要です。
ノードのドレイン
メンテナンス準備として、ノードをスケジューリング不可にしてワークロードを退避させます。
# <node-to-drain>をドレインするノード名に置き換えてください
kubectl drain <node-to-drain> --ignore-daemonsets
kubeletとkubectlのアップグレード
-
kubeletとkubectlをアップグレードします。
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.34.x-*' kubectl='1.34.x-*' && \ sudo apt-mark hold kubelet kubectlDNFを使うシステム:
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo yum install -y kubelet-'1.34.x-*' kubectl-'1.34.x-*' --disableexcludes=kubernetesDNF5を使うシステム:
# 1.34.x-*のxを、今回のアップグレードで選んだ最新パッチに置き換えてください sudo yum install -y kubelet-'1.34.x-*' kubectl-'1.34.x-*' --setopt=disable_excludes=kubernetes -
kubeletを再起動します。
sudo systemctl daemon-reload sudo systemctl restart kubelet
ノードのuncordon(スケジュール可能化)
ノードを再びスケジュール可能にしてオンラインにします。
# <node-to-uncordon>を対象ノード名に置き換えてください
kubectl uncordon <node-to-uncordon>
ワーカーノードのアップグレード
ワーカーノードのアップグレードは、ワークロードを実行するための必要最小限の容量を損なわない範囲で、ノードを1台ずつまたは複数台ずつ順に実行してください。
LinuxとWindowsのワーカーノードのアップグレード方法については次のページを参照してください。
クラスターの状態を確認する
kubeletをすべてのノードでアップグレードした後、kubectlがクラスターにアクセス可能な場所から以下のコマンドを実行し、すべてのノードが再び利用可能であることを確認してください。
kubectl get nodes
STATUS列にはすべてのノードでReadyが表示され、バージョン番号が更新されているはずです。
障害状態からの復旧
kubeadm upgradeが失敗してロールバックしない場合(例えば実行中の予期しないシャットダウンなど)、再度kubeadm upgradeを実行することで回復できます。kubeadm upgradeは冪等性があり、最終的に実際の状態が宣言した望ましい状態であることを保証します。
悪い状態から回復するため、クラスターが実行しているバージョンを変更せずにsudo kubeadm upgrade apply --forceを実行することもできます。
アップグレード中、kubeadmは/etc/kubernetes/tmpの下に次のバックアップフォルダを書き込みます。
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>
kubeadm-backup-etcdにはこのコントロールプレーンノードのローカルetcdメンバーデータのバックアップが含まれます。etcdのアップグレードに失敗し、自動ロールバックが機能しない場合、このフォルダの内容を/var/lib/etcdに手動で復元できます。外部etcdを使用している場合、このバックアップフォルダは空になります。
kubeadm-backup-manifestsにはこのコントロールプレーンノードのStatic Podマニフェストファイルのバックアップが含まれます。アップグレードの失敗や自動ロールバックが機能しない場合、このフォルダの内容を/etc/kubernetes/manifestsに手動で復元できます。何らかの理由で特定のコンポーネントのアップグレード前とアップグレード後のマニフェストに差分がない場合、そのコンポーネントのバックアップファイルは書き込まれません。
備考:
kubeadmを使ったクラスターのアップグレード後、バックアップディレクトリ/etc/kubernetes/tmpは残り、これらのバックアップファイルは手動で削除する必要があります。動作の仕組み
kubeadm upgrade applyは次のことを行います。
- クラスターがアップグレード可能な状態であることをチェックする。
- APIサーバーに到達可能であること
- すべてのノードが
Ready状態であること - コントロールプレーンが健全であること
- バージョンスキューポリシーを適用する。
- コントロールプレーンのイメージが利用可能であるか、あるいはマシンにプル可能であることを確認する。
- コンポーネント設定がバージョンアップを必要とする場合、代替を生成し、および/またはユーザー提供の上書きを使用する。
- コントロールプレーンコンポーネントをアップグレードするか、いずれかが起動しない場合はロールバックする。
- 新しい
CoreDNSとkube-proxyマニフェストを適用し、必要なRBACルールが作成されていることを確認する。 - APIサーバーの新しい証明書とキーを作成し、期限が180日以内に切れる場合は古いファイルをバックアップする。
kubeadm upgrade nodeは追加のコントロールプレーンノードで次のことを行います。
- kubeadmの
ClusterConfigurationをクラスターから取得する。 - オプションでkube-apiserverの証明書をバックアップする。
- コントロールプレーンコンポーネントのStatic Podマニフェストをアップグレードする。
- このノードのkubelet設定をアップグレードする。
kubeadm upgrade nodeはワーカーノードで次のことを行います。
- kubeadmの
ClusterConfigurationをクラスターから取得する。 - このノードのkubelet設定をアップグレードする。
1.4 - Windowsノードの追加
Kubernetes v1.18 [beta]
Kubernetesを使用してLinuxノードとWindowsノードを混在させて実行できるため、Linuxで実行するPodとWindowsで実行するPodを混在させることができます。このページでは、Windowsノードをクラスターに登録する方法を示します。
始める前に
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17.バージョンを確認するには次のコマンドを実行してください: kubectl version.
-
WindowsコンテナをホストするWindowsノードを構成するには、Windows Server 2019ライセンス(またはそれ以上)を取得します。 VXLAN/オーバーレイネットワークを使用している場合は、KB4489899もインストールされている必要があります。
-
コントロールプレーンにアクセスできるLinuxベースのKubernetes kubeadmクラスター(kubeadmを使用したシングルコントロールプレーンクラスターの作成を参照)
目標
- Windowsノードをクラスターに登録する
- LinuxとWindowsのPodとServiceが相互に通信できるようにネットワークを構成する
はじめに: クラスターへのWindowsノードの追加
ネットワーク構成
LinuxベースのKubernetesコントロールプレーンノードを取得したら、ネットワーキングソリューションを選択できます。このガイドでは、簡単にするためにVXLANモードでのFlannelの使用について説明します。
Flannel構成
-
FlannelのためにKubernetesコントロールプレーンを準備する
クラスター内のKubernetesコントロールプレーンでは、多少の準備が推奨されます。Flannelを使用する場合は、iptablesチェーンへのブリッジIPv4トラフィックを有効にすることをお勧めします。すべてのLinuxノードで次のコマンドを実行する必要があります:
sudo sysctl net.bridge.bridge-nf-call-iptables=1 -
Linux用のFlannelをダウンロードして構成する
最新のFlannelマニフェストをダウンロード:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlVNIを4096、ポートを4789に設定するために、flannelマニフェストの
net-conf.jsonセクションを変更します。次のようになります:net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan", "VNI" : 4096, "Port": 4789 } }備考:
Linux上のFlannelがWindows上のFlannelと相互運用するには、VNIを4096およびポート4789に設定する必要があります。これらのフィールドの説明については、VXLANドキュメントを参照してください。備考:
L2Bridge/Host-gatewayモードを使用するには、代わりにTypeの値を"host-gw"に変更し、VNIとPortを省略します。 -
Flannelマニフェストを適用して検証する
Flannelの構成を適用しましょう:
kubectl apply -f kube-flannel.yml数分後、Flannel Podネットワークがデプロイされていれば、すべてのPodが実行されていることがわかります。
kubectl get pods -n kube-system出力結果には、実行中のLinux flannel DaemonSetが含まれているはずです:
NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system kube-flannel-ds-54954 1/1 Running 0 1m -
Windows Flannelとkube-proxy DaemonSetを追加する
これで、Windows互換バージョンのFlannelおよびkube-proxyを追加できます。 互換性のあるバージョンのkube-proxyを確実に入手するには、イメージのタグを置換する必要があります。 次の例は、Kubernetes 1.34.0の使用方法を示していますが、 独自のデプロイに合わせてバージョンを調整する必要があります。
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.34.0/g' | kubectl apply -f - kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml備考:
ホストゲートウェイを使用している場合は、代わりに https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml を使用してください。備考:
Windowsノードでイーサネット(「Ethernet0 2」など)ではなく別のインターフェースを使用している場合は、次の行を変更する必要があります:
wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"flannel-host-gw.ymlまたはflannel-overlay.ymlファイルで、それに応じてインターフェースを指定します。# 例 curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
Windowsワーカーノードの参加
備考:
Containers機能をインストールし、Dockerをインストールする必要があります。
行うための指示としては、Dockerエンジンのインストール - Windowsサーバー上のエンタープライズを利用できます。備考:
Windowsセクションのすべてのコードスニペットは、 Windowsワーカーノードの(管理者)権限を持つPowerShell環境で実行されます。-
wins、kubelet、kubeadmをインストールします。
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1 .\PrepareNode.ps1 -KubernetesVersion v1.34.0 -
kubeadmを実行してノードに参加しますコントロールプレーンホストで
kubeadm initを実行したときに提供されたコマンドを使用します。 このコマンドがなくなった場合、またはトークンの有効期限が切れている場合は、kubeadm token create --print-join-command(コントロールプレーンホスト上で)を実行して新しいトークンを生成します。
インストールの確認
次のコマンドを実行して、クラスター内のWindowsノードを表示できるようになります:
kubectl get nodes -o wide
新しいノードがNotReady状態の場合は、flannelイメージがまだダウンロード中の可能性があります。
kube-system名前空間のflannel Podを確認することで、以前と同様に進行状況を確認できます:
kubectl -n kube-system get pods -l app=flannel
flannel Podが実行されると、ノードはReady状態になり、ワークロードを処理できるようになります。
次の項目
1.5 - Windowsノードのアップグレード
Kubernetes v1.18 [beta]
このページでは、kubeadmで作られたWindowsノードをアップグレードする方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17.バージョンを確認するには次のコマンドを実行してください: kubectl version.
- 残りのkubeadmクラスターをアップグレードするプロセスを理解します。 Windowsノードをアップグレードする前にコントロールプレーンノードをアップグレードしたいと思うかもしれません。
ワーカーノードをアップグレード
kubeadmをアップグレード
-
Windowsノードから、kubeadmをアップグレードします。:
# 1.34.0を目的のバージョンに置き換えます curl.exe -Lo C:\k\kubeadm.exe https://dl.k8s.io/v1.34.0/bin/windows/amd64/kubeadm.exe
ノードをドレインする
-
Kubernetes APIにアクセスできるマシンから、 ノードをスケジュール不可としてマークして、ワークロードを削除することでノードのメンテナンスを準備します:
# <node-to-drain>をドレインするノードの名前に置き換えます kubectl drain <node-to-drain> --ignore-daemonsetsこのような出力結果が表示されるはずです:
node/ip-172-31-85-18 cordoned node/ip-172-31-85-18 drained
kubeletの構成をアップグレード
-
Windowsノードから、次のコマンドを呼び出して新しいkubelet構成を同期します:
kubeadm upgrade node
kubeletをアップグレード
-
Windowsノードから、kubeletをアップグレードして再起動します:
stop-service kubelet curl.exe -Lo C:\k\kubelet.exe https://dl.k8s.io/v1.34.0/bin/windows/amd64/kubelet.exe restart-service kubelet
ノードをオンライン状態に
-
Kubernetes APIにアクセスできるマシンから、 スケジュール可能としてマークして、ノードをオンラインに戻します:
# <node-to-drain>をノードの名前に置き換えます kubectl uncordon <node-to-drain>
kube-proxyをアップグレード
-
Kubernetes APIにアクセスできるマシンから、次を実行します、 もう一度1.34.0を目的のバージョンに置き換えます:
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.34.0/g' | kubectl apply -f -
1.6 - kubeadmによる証明書管理
Kubernetes v1.15 [stable]
kubeadmで生成されたクライアント証明書は1年で失効します。 このページでは、kubeadmで証明書の更新を管理する方法について説明します。 また、kubeadmによる証明書管理に関連するタスクも説明します。
Kubernetesプロジェクトでは、最新のパッチリリースに速やかにアップグレードし、サポートされているKubernetesのマイナーリリースを実行していることを推奨しています。 この推奨事項に従うことで、セキュリティを維持できます。
始める前に
KubernetesにおけるPKI証明書と要件を熟知している必要があります。
kubeadmコマンドに対して、kubeadmの設定ファイルを渡す方法について熟知している必要があります。
本ページではopensslコマンド(手動で証明書に署名する場合に使用)の使用方法について説明しますが、他のツールで代用することもできます。
ここで紹介する手順の一部では、管理者アクセスにsudoを使用していますが、同等のツールを使用しても構いません。
カスタム証明書の使用
デフォルトでは、kubeadmはクラスターの実行に必要なすべての証明書を生成します。 独自の証明書を提供することで、この動作をオーバーライドできます。
そのためには、--cert-dirフラグまたはkubeadmのClusterConfigurationのcertificatesDirフィールドで指定された任意のディレクトリに配置する必要があります。
デフォルトは/etc/kubernetes/pkiです。
kubeadm initを実行する前に既存の証明書と秘密鍵のペアが存在する場合、kubeadmはそれらを上書きしません。
つまり、例えば既存のCAを/etc/kubernetes/pki/ca.crtと/etc/kubernetes/pki/ca.keyにコピーすれば、kubeadmは残りの証明書に署名する際、このCAを使用できます。
暗号化アルゴリズムの選択
kubeadmでは、公開鍵や秘密鍵を作成する際に暗号化アルゴリズムを選択できます。
設定するには、kubeadmの設定ファイルにてencryptionAlgorithmフィールドを使用します。
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
encryptionAlgorithm: <ALGORITHM>
<ALGORITHM>は、RSA-2048(デフォルト)、RSA-3072、RSA-4096、ECDSA-P256が選択できます。
証明書の有効期間の選択
kubeadmでは、CAおよびリーフ証明書の有効期間を選択可能です。
設定するには、kubeadmの設定ファイルにて、certificateValidityPeriod、caCertificateValidityPeriodフィールドを使用します。
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
certificateValidityPeriod: 8760h # デフォルト: 365日 × 24時間 = 1年
caCertificateValidityPeriod: 87600h # デフォルト: 365日 × 24時間 * 10 = 10年
フィールドの値は、Go言語のtime.Durationの値で許容される形式に準拠しており、サポートされている最長単位はh(時間)です。
外部CAモード
また、ca.crtファイルのみを提供し、ca.keyファイルを提供しないことも可能です(これはルートCAファイルのみに有効で、他の証明書ペアには有効ではありません)。
他の証明書とkubeconfigファイルがすべて揃っている場合、kubeadmはこの状態を認識し、「外部CA」モードを有効にします。
kubeadmはディスク上のCAキーがなくても処理を進めます。
代わりに、--controllers=csrsignerを使用してController-managerをスタンドアロンで実行し、CA証明書と鍵を指定します。
外部CAモードを使用する場合、コンポーネントの資格情報を作成する方法がいくつかあります。
手動によるコンポーネント資格情報の作成
PKI証明書とその要件には、kubeadmコンポーネントに必要な全ての資格情報を手動で作成する方法が記載されています。
本ページではopensslコマンド(手動で証明書を署名する場合に使用)の使用方法について説明しますが、他のツールを代用することもできます。
kubeadmによって生成されたCSRへの署名による資格情報の作成
kubeadmは、opensslのようなツールと外部CAを使用して手動で署名可能なCSRファイルの生成ができます。
これらのCSRファイルには、kubeadmによってデプロイされるコンポーネントに必要な資格情報の全ての仕様が含まれます。
kubeadm phaseを使用したコンポーネント資格情報の自動作成
もしくは、kubeadm phaseコマンドを使用して、これらのプロセスを自動化することが可能です。
- kubeadmコントロールプレーンノードとして外部CAを用いて構築するホストに対し、アクセスします。
- 外部CAの
ca.crtとca.keyファイルを、ノードの/etc/kubernetes/pkiへコピーします。 kubeadm initで使用する、config.yamlという一時的なkubeadmの設定ファイルを準備します。 このファイルには、ClusterConfiguration.controlPlaneEndpoint、ClusterConfiguration.certSANs、InitConfiguration.APIEndpointなど、証明書に含まれる可能性のある、クラスター全体またはホスト固有の関連情報が全て記載されていることを確認します。- 同じホストで
kubeadm init phase kubeconfig all --config config.yamlおよびkubeadm init phase certs all --config config.yamlコマンドを実行します。 これにより、必要な全てのkubeconfigファイルと証明書が/etc/kubernetes/配下およびpkiサブディレクトリ配下に作成されます。 - 作成されたファイルを調べます。
/etc/kubernetes/pki/ca.keyを削除し、/etc/kubernetes/super-admin.confを削除するか、安全な場所に退避します。 kubeadm joinを実行するノードでは、/etc/kubernetes/kubelet.confも削除します。 このファイルはkubeadm initが実行される最初のノードでのみ必要とされます。pki/sa.*、pki/front-proxy-ca.*、pki/etc/ca.*等のファイルは、コントロールプレーンノード間で共有されます。kubeadm joinを実行するノードに手動で証明書を配布するか、kubeadm initの--upload-certsオプションおよびkubeadm joinの--certificate-keyオプションを使用することでこれらを自動配布します。
全てのノードにて資格情報を準備した後、これらのノードをクラスターに参加させるためにkubeadm initおよびkubeadm joinを実行します。
kubeadmは/etc/kubernetes/およびpkiサブディレクトリ配下に存在するkubeconfigと証明書を使用します。
証明書の有効期限と管理
備考:
kubeadmは、外部CAによって署名された証明書を管理することができません。check-expirationサブコマンドを使うと、証明書の有効期限を確認することができます。
kubeadm certs check-expiration
このような出力になります:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
このコマンドは、/etc/kubernetes/pkiフォルダー内のクライアント証明書と、kubeadmが使用するkubeconfigファイル(admin.conf、controller-manager.conf、scheduler.conf)に埋め込まれたクライアント証明書の有効期限/残余時間を表示します。
また、証明書が外部管理されている場合、kubeadmはユーザーに通知します。この場合、ユーザーは証明書の更新を手動または他のツールを使用して管理する必要があります。
kubeadmは/var/lib/kubelet/pki配下にあるローテーション可能な証明書でkubeletの証明書の自動更新を構成するため、kubelet.confは上記のリストに含まれません。
期限切れのkubeletクライアント証明書を修復するには、kubeletクライアント証明書のローテーションに失敗するを参照ください。
備考:
kubeadm version 1.17より前のkubeadm initで作成したノードでは、kubelet.confの内容を手動で変更しなければならないというバグが存在します。
kubeadm initが終了したら、client-certificate-dataとclient-key-dataを置き換えて、ローテーションされたkubeletクライアント証明書を指すようにkubelet.confを更新してください。
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
証明書の自動更新
kubeadmはコントロールプレーンのアップグレード時にすべての証明書を更新します。
この機能は、最もシンプルなユースケースに対応するために設計されています。 証明書の更新に特別な要件がなく、Kubernetesのバージョンアップを定期的に行う場合(各アップグレードの間隔が1年未満)、kubeadmは、クラスターを最新に保ち、適切なセキュリティを確保します。
証明書の更新に関してより複雑な要求がある場合は、--certificate-renewal=falseをkubeadm upgrade applyやkubeadm upgrade nodeに渡して、デフォルトの動作から外れるようにすることができます。
手動による証明書更新
適切なコマンドラインオプションを指定してkubeadm certs renewコマンドを実行すれば、いつでも証明書を手動で更新できます。
複数のコントロールプレーンによってクラスターが稼働している場合、全てのコントロールプレーンノード上でこのコマンドを実行する必要があります。
このコマンドは/etc/kubernetes/pkiに格納されているCA(またはfront-proxy-CA)の証明書と鍵を使用して更新を行います。
kubeadm certs renewは、属性(Common Name、Organization、SANなど)の信頼できるソースとして、kubeadm-config ConfigMapではなく、既存の証明書を使用します。
それでも、Kubernetesプロジェクトでは、混乱のリスクを避けるために証明書とConfigMap内の関連した値を同期したままにしておくことを推奨しています。
コマンド実行後、コントロールプレーンのPodを再起動する必要があります。
これは、現在は動的な証明書のリロードが、すべてのコンポーネントと証明書でサポートされているわけではないため、必要な作業です。
static Podはローカルkubeletによって管理され、APIサーバーによって管理されないため、kubectlで削除および再起動することはできません。
static Podを再起動するには、一時的に/etc/kubernetes/manifests/からマニフェストファイルを削除して20秒間待ちます(KubeletConfiguration構造体のfileCheckFrequency値を参照してください)。
マニフェストディレクトリにてマニフェストファイルが存在しなくなると、kubeletはPodを終了します。
その後ファイルを戻し、さらにfileCheckFrequency期間後に、kubeletはPodを再作成し、コンポーネントの証明書更新を完了することができます。
kubeadm certs renewは、特定の証明書を更新できます。
また、allサブコマンドを用いることで全ての証明書を更新できます。
# 複数のコントロールプレーンによってクラスターが稼働している場合、このコマンドは全てのコントロールプレーン上で実行する必要があります。
kubeadm certs renew all
管理者用の証明書のコピー(オプション)
kubeadmで構築されたクラスターでは、多くの場合、kubeadmを使用したクラスターの作成の指示に従い、admin.conf証明書が$HOME/.kube/configへコピーされます。
このようなシステムでは、admin.confを更新した後に$HOME/.kube/configの内容を更新するため、次のコマンドを実行します。
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Kubernetes certificates APIによる証明書の更新
ここでは、Kubernetes certificates APIを使用して手動で証明書更新を実行する方法について詳しく説明します。
注意:
これらは、組織の証明書インフラをkubeadmで構築されたクラスターに統合する必要があるユーザー向けの上級者向けのトピックです。 kubeadmのデフォルトの設定で満足できる場合は、代わりにkubeadmに証明書を管理させる必要があります。署名者の設定
Kubernetesの認証局は、そのままでは機能しません。 cert-managerなどの外部署名者を設定するか、組み込みの署名者を使用することができます。
ビルトインサイナーはkube-controller-managerに含まれるものです。
ビルトインサイナーを有効にするには、--cluster-signing-cert-fileと--cluster-signing-key-fileフラグを渡す必要があります。
新しいクラスターを作成する場合は、kubeadm設定ファイルを使用します。
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
controllerManager:
extraArgs:
- name: "cluster-signing-cert-file"
value: "/etc/kubernetes/pki/ca.crt"
- name: "cluster-signing-key-file"
value: "/etc/kubernetes/pki/ca.key"
証明書署名要求(CSR)の作成
Kubernetes APIでのCSR作成については、CertificateSigningRequestの作成を参照ください。
外部CAによる証明書の更新
ここでは、外部認証局を利用して手動で証明書更新を行う方法について詳しく説明します。
外部CAとの連携を強化するために、kubeadmは証明書署名要求(CSR)を生成することもできます。 CSRとは、クライアント用の署名付き証明書をCAに要求することを表します。 kubeadmでは、通常ディスク上のCAによって署名される証明書をCSRとして生成することができます。しかし、CAはCSRとして生成することはできません。
証明書署名要求(CSR)による証明書の更新
証明書の更新は、新たなCSRを作成し外部CAで署名することで実施できます。 kubeadmによって生成されたCSRの署名についての詳細は、kubeadmによって生成された証明書署名要求(CSR)の署名セクションを参照してください。
認証局(CA)のローテーション
kubeadmは、CA証明書のローテーションや置換を標準ではサポートしていません。
CAの手動ローテーションや置換についての詳細は、CA証明書の手動ローテーションを参照してください。
署名付きkubeletサーバー証明書の有効化
デフォルトでは、kubeadmによって展開されるkubeletサーバー証明書は自己署名されています。 これは、metrics-serverのような外部サービスからkubeletへの接続がTLSで保護されないことを意味します。
新しいkubeadmクラスター内のkubeletが適切に署名されたサーバー証明書を取得するように設定するには、kubeadm initに以下の最小限の設定を渡す必要があります。
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
すでにクラスターを作成している場合は、以下の手順で適応させる必要があります。
kube-systemnamespace中のkubelet-configConfigMapを探して編集します。 このConfigMap内には、kubeletキーの値として、KubeletConfigurationに関する記述が存在します。 KubeletConfigurationの内容を編集し、serverTLSBootstrap: trueを設定します。- 各ノードで、
/var/lib/kubelet/config.yamlにserverTLSBootstrap: trueフィールドを追加し、systemctl restart kubeletでkubeletを再起動します。
serverTLSBootstrap: trueフィールドは、certificates.k8s.io APIからkubeletのサーバー証明書をリクエストすることで、kubeletサーバー証明書のブートストラップを有効にします。
既知の制限事項の1つとして、これらのCSR(証明書署名要求)はkube-controller-managerのデフォルトの署名者によって自動的に承認されないことが挙げられます。
kubernetes.io/kubelet-servingを参照してください。
これには、ユーザーまたはサードパーティのコントローラーからのアクションが必要です。
これらのCSRは、以下を使用して表示できます:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
承認するためには、次のようにします:
kubectl certificate approve <CSR-name>
デフォルトでは、これらのサーバー証明書は1年後に失効します。
kubeadmはKubeletConfigurationフィールドのrotateCertificatesをtrueに設定します。
これは有効期限が切れる間際に、サーバー証明書のための新しいCSRセットを作成し、ローテーションを完了するために承認する必要があることを意味します。
詳しくは証明書のローテーションを参照してください。
これらのCSRを自動的に承認するためのソリューションをお探しの場合は、クラウドプロバイダーに連絡し、ノードの識別をアウトオブバンドのメカニズムで行うCSRの署名者がいるかどうか確認することをお勧めします。
サードパーティのカスタムコントローラーを使用することができます。
このようなコントローラーは、CSRのCommonNameを検証するだけでなく、要求されたIPやドメイン名も検証しなければ、安全なメカニズムとは言えません。 これにより、kubeletクライアント証明書にアクセスできる悪意のあるアクターが、任意のIPやドメイン名に対してサーバー証明書を要求するCSRを作成することを防止できます。
追加ユーザー用のkubeconfigファイルの生成
クラスターの構築中、kubeadm initはsuper-admin.conf内の証明書に署名し、Subject: O = system:masters, CN = kubernetes-super-adminを設定します。
system:mastersは認可のレイヤーをバイパスする(例: RBAC)、緊急用のスーパーユーザーグループです。
admin.confファイルもkubeadmによってコントロールプレーン上に作成され、Subject: O = kubeadm:cluster-admins, CN = kubernetes-adminと設定された証明書が含まれています。
kubeadm:cluster-adminsはkubeadmが属している論理的なグループです。
RBAC(kubeadmのデフォルト)をクラスターに使用している場合、kubeadm:cluster-adminsグループはcluster-admin ClusterRoleにバインドされます。
警告:
super-admin.confおよびadmin.confファイルを共有しないでください。
代わりに、管理者として従事するユーザーに対しても最小限のアクセス権限を作成し、緊急アクセス以外の場合にはその最小限の権限の代替手段を使用します。kubeadm kubeconfig userコマンドを使用することで、追加ユーザー用のkubeconfigファイルを生成できます。
このコマンドは、コマンドラインフラグとkubeadm configurationオプションの組み合わせが可能です。
生成されたkubeconfigファイルはstdoutに書き込まれ、kubeadm kubeconfig user ... > somefile.confを使用してファイルにパイプすることができます。
--configで使用できる設定ファイルの例:
# example.yaml
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
# kubeconfig内にて、対象の"cluster"として使用します。
clusterName: "kubernetes"
# kubeconfig内にて、このクラスターの"server"(IPもしくはDNS名)として使用します。
controlPlaneEndpoint: "some-dns-address:6443"
# クラスターCAの秘密鍵と証明書が、このローカルディレクトリからロードされます。
certificatesDir: "/etc/kubernetes/pki"
これらの設定が、目的の対象クラスターの設定と一致していることを確認します。 既存のクラスターの設定を表示するには、次のコマンドを使用します。
kubectl get cm kubeadm-config -n kube-system -o=jsonpath="{.data.ClusterConfiguration}"
次の例では、appdevsグループに属する新しいユーザーjohndoeに対して24時間有効な資格情報を含むkubeconfigファイルが生成されます。
kubeadm kubeconfig user --config example.yaml --org appdevs --client-name johndoe --validity-period 24h
次の例では、1週間有効な管理者の資格情報を持つkubeconfigファイルが生成されます。
kubeadm kubeconfig user --config example.yaml --client-name admin --validity-period 168h
kubeadmによって生成された証明書署名要求(CSR)の署名
kubeadm certs generate-csrコマンドで、証明書署名要求を作成できます。
通常の証明書については、このコマンドの実行によって.csr/.keyファイルのペアが生成されます。
kubeconfigに埋め込まれた証明書については、このコマンドで.csr/.confのペアが生成されます。このペアでは、鍵は.confファイルに埋め込まれています。
CSRファイルには、CAが証明書に署名するために必要な情報が全て含まれています。 kubeadmは全ての証明書とCSRに対し、明確に定義された仕様を適用します。
証明書のデフォルトのディレクトリは/etc/kubernetes/pkiであり、kubeconfigファイルのデフォルトのディレクトリは/etc/kubernetesです。
これらのデフォルトのディレクトリは、それぞれ--cert-dirと--kubeconfig-dirフラグで上書きできます。
kubeadm certs generate-csrにカスタムオプションを渡すには、--configフラグを使用します。
このフラグは、kubeadm initと同様に、kubeadmの設定ファイルを受け入れます。
追加のSANやカスタムIPアドレスなどの指定については、関連の全てのkubeadmコマンドに使用するために、全て同じ設定ファイルに保存し、--configとして渡す必要があります。
備考:
このガイドでは、Kubernetesのデフォルトのディレクトリである/etc/kubernetesを使用しています。このディレクトリにはスーパーユーザー権限が必要です。
このガイドに従って、書き込み可能なディレクトリを使用している場合(通常は--cert-dirと--kubeconfig-dirを指定してkubeadmを実行します)は、sudoコマンドを省略できます。
次に、作成したファイルを/etc/kubernetesディレクトリ内にコピーして、kubeadm initもしくはkubeadm joinがこれらのファイルを検出できるようにする必要があります。
CAとサービスアカウントファイルの準備
kubeadm initを実行する最初のコントロールプレーンノードでは、以下のコマンドを実行してください。
sudo kubeadm init phase certs ca
sudo kubeadm init phase certs etcd-ca
sudo kubeadm init phase certs front-proxy-ca
sudo kubeadm init phase certs sa
これにより、コントロールプレーンノードでkubeadmが必要とする、全ての自己署名CAファイル(証明書と鍵)とサービスアカウント(公開鍵と秘密鍵)が/etc/kubernetes/pkiおよび/etc/kubernetes/pki/etcdフォルダーに作成されます。
備考:
外部CAを使用する場合、同じファイルをアウトオブバンドで作成し、最初のコントロールプレーンノードの/etc/kubernetesへ手動でコピーする必要があります。
全ての証明書に署名した後、外部CAモードセクションの記載のように、ルートCAの鍵(ca.key)は削除しても構いません。
2番目以降のコントロールプレーンノード(kubeadm join --control-planeを実行します)では、上記のコマンドを実行する必要はありません。
高可用性クラスターの構築方法に応じて、最初のコントロールプレーンノードから同じファイルを手動でコピーするか、kubeadm initの自動化された--upload-certs機能を使用する必要があります。
CSRの生成
kubeadm certs generate-csrコマンドは、kubeadmによって管理される全ての既知の証明書のCSRファイルを作成します。
コマンドの実行後、不要な.csr、.conf、または.keyファイルを手動で削除する必要があります。
kubelet.confに対する考慮事項
このセクションはコントロールプレーンノードとワーカーノードの両方に適用されます。
ca.keyファイルをコントロールプレーンから削除している場合(外部CAモード)、クラスターで実行中のkube-controller-managerはkubeletクライアント証明書への署名ができなくなります。
構成内にこれらの証明書へ署名するための外部の方法(外部署名者など)が存在しない場合は、このガイドで説明されているように、kubelet.conf.csrに手動で署名できます。
なお、これにより、自動によるkubeletクライアント証明書のローテーションが無効になることに注意してください。
その場合は、証明書の有効期限が近づいたら、新しいkubelet.conf.csrを生成し、証明書に署名してkubelet.confに埋め込み、kubeletを再起動する必要があります。
ca.keyファイルがコントロールプレーンノード上に存在する場合、2番目以降のコントロールプレーンノードおよびワーカーノード(kubeadm join ...を実行する全てのノード)では、kubelet.conf.csrの処理をスキップできます。
これは、実行中のkube-controller-managerが新しいkubeletクライアント証明書の署名を担当するためです。
備考:
kubelet.conf.csrファイルは、最初のコントロールプレーンノード(最初にkubeadm initを実行したホスト)で処理する必要があります。
これは、kubeadmがそのノードをクラスターのブートストラップ用のノードと見なすため、事前に設定されたkubelet.confが必要になるためです。コントロールプレーンノード
1番目(kubeadm init)および2番目以降(kubeadm join --control-plane)のコントロールプレーンノードで以下のコマンドを実行し、全てのCSRファイルを生成します。
sudo kubeadm certs generate-csr
外部etcdを使用する場合は、kubeadmとetcdノードに必要なCSRファイルについて理解するために、kubeadmを使用した外部etcdのガイドを参照してください。
/etc/kubernetes/pki/etcd配下にある他の.csrおよび.keyファイルは削除して構いません。
kubelet.confに対する考慮事項の説明に基づいて、kubelet.confおよびkubelet.conf.csrファイルを保持するか削除します。
ワーカーノード
kubelet.confに対する考慮事項の説明に基づいて、オプションで以下のコマンドを実行し、kubelet.confおよびkubelet.conf.csrファイルを保持します。
sudo kubeadm certs generate-csr
あるいは、ワーカーノードの手順を完全にスキップします。
全ての証明書のCSRへ署名
備考:
外部CAを使用し、openssl用のCAのシリアル番号ファイル(.srl)が既に存在する場合は、これらのファイルをCSRを署名するkubeadmノードにコピーできます。
コピーする.srlファイルは、/etc/kubernetes/pki/ca.srl、/etc/kubernetes/pki/front-proxy-ca.srlおよび/etc/kubernetes/pki/etcd/ca.srlです。
その後、これらのファイルをCSRファイルに署名する新たなノードに移動できます。
ノード上のCAに対して.srlファイルが存在しない場合、以下のスクリプトはランダムな開始シリアル番号を持つ新規のSRLファイルを生成します。
.srlファイルの詳細については、opensslドキュメントの--CAserialフラグを参照してください。
CSRファイルが存在する全てのノードで、この手順を繰り返してください。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
このスクリプトは、/etc/kubernetesツリー以下に存在する全てのCSRファイルに対する証明書ファイルを生成します。
#!/bin/bash
# 日単位で証明書の有効期間を設定
DAYS=365
# front-proxyとetcdを除いた全てのCSRファイルへ署名
find ./ -name "*.csr" | grep -v "pki/etcd" | grep -v "front-proxy" | while read -r FILE;
do
echo "* Processing ${FILE} ..."
FILE=${FILE%.*} # 拡張子を取り除く
if [ -f "./pki/ca.srl" ]; then
SERIAL_FLAG="-CAserial ./pki/ca.srl"
else
SERIAL_FLAG="-CAcreateserial"
fi
openssl x509 -req -days "${DAYS}" -CA ./pki/ca.crt -CAkey ./pki/ca.key ${SERIAL_FLAG} \
-in "${FILE}.csr" -out "${FILE}.crt"
sleep 2
done
# 全てのetcdのCSRへ署名
find ./pki/etcd -name "*.csr" | while read -r FILE;
do
echo "* Processing ${FILE} ..."
FILE=${FILE%.*} # 拡張子を取り除く
if [ -f "./pki/etcd/ca.srl" ]; then
SERIAL_FLAG=-CAserial ./pki/etcd/ca.srl
else
SERIAL_FLAG=-CAcreateserial
fi
openssl x509 -req -days "${DAYS}" -CA ./pki/etcd/ca.crt -CAkey ./pki/etcd/ca.key ${SERIAL_FLAG} \
-in "${FILE}.csr" -out "${FILE}.crt"
done
# front-proxyのCSRへ署名
echo "* Processing ./pki/front-proxy-client.csr ..."
openssl x509 -req -days "${DAYS}" -CA ./pki/front-proxy-ca.crt -CAkey ./pki/front-proxy-ca.key -CAcreateserial \
-in ./pki/front-proxy-client.csr -out ./pki/front-proxy-client.crt
kubeconfigファイルへの証明書の組み込み
CSRファイルが存在する全てのノードで、この手順を繰り返してください。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
このスクリプトは、前の手順でCSRファイルからkubeconfigファイル用に署名された.crtファイルを取得し、これらをkubeconfigファイルに組み込みます。
#!/bin/bash
CLUSTER=kubernetes
find ./ -name "*.conf" | while read -r FILE;
do
echo "* Processing ${FILE} ..."
KUBECONFIG="${FILE}" kubectl config set-cluster "${CLUSTER}" --certificate-authority ./pki/ca.crt --embed-certs
USER=$(KUBECONFIG="${FILE}" kubectl config view -o jsonpath='{.users[0].name}')
KUBECONFIG="${FILE}" kubectl config set-credentials "${USER}" --client-certificate "${FILE}.crt" --embed-certs
done
クリーンアップの実行
CSRファイルがあるすべてのノードでこの手順を実行します。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
#!/bin/bash
# CSRファイルのクリーンアップ
rm -f ./*.csr ./pki/*.csr ./pki/etcd/*.csr # 全てのCSRファイルを削除します。
# kubeconfigファイル内に既に埋め込まれているCRTファイルのクリーンアップ
rm -f ./*.crt
必要に応じて、.srlファイルを次に使用するノードへ移動させます。
必要に応じて、外部CAを使用する場合は、外部CAモードのセクションで説明されているように、/etc/kubernetes/pki/ca.keyファイルを削除します。
kubeadmノードの初期化
CSRファイルに署名し、ノードとして使用する各ホストへ証明書を配置すると、kubeadm initコマンドとkubeadm joinを使用してKubernetesクラスターを構築できます。
initとjoinの実行時、kubeadmは各ホストのローカルファイルシステムの/etc/kubernetesツリーで検出した既存の証明書、暗号化キー、およびkubeconfigファイルを使用します。
2 - dockershimからの移行
dockershimから他のコンテナランタイムに移行する際に知っておくべき情報を紹介します。
Kubernetes 1.20でdockershim deprecationが発表されてから、様々なワークロードやKubernetesインストールにどう影響するのかという質問が寄せられています。
この問題をよりよく理解するために、dockershimの削除に関するFAQブログが役に立つでしょう。
dockershimから代替のコンテナランタイムに移行することが推奨されます。 コンテナランタイムのセクションをチェックして、どのような選択肢があるかを確認してください。 問題が発生した場合は、必ず問題の報告をしてください。 そうすれば、問題が適時に修正され、クラスターがdockershimの削除に対応できるようになります。
2.1 - ノードのコンテナランタイムをDocker Engineからcontainerdに変更する
このタスクでは、コンテナランタイムをDockerからcontainerdに更新するために必要な手順について説明します。 これは、Kubernetes 1.23以前を使用しているクラスターオペレーターに適用されます。 また、dockershimからcontainerdへの移行を行う際の具体的なシナリオ例も含まれています。 代替のコンテナランタイムについては、このページを参照してください。
始める前に
containerdをインストールします。 詳細についてはcontainerdのインストールドキュメントを参照してください。 特定の前提条件については、containerdガイドを参照してください。
ノードのドレイン
kubectl drain <node-to-drain> --ignore-daemonsets
<node-to-drain>は、ドレイン対象のノード名に置き換えてください。
Dockerデーモンの停止
systemctl stop kubelet
systemctl disable docker.service --now
containerdのインストール
containerdをインストールする手順の詳細については、ガイドを参照してください。
-
公式のDockerリポジトリから
containerd.ioパッケージをインストールします。 各Linuxディストリビューション向けにDockerリポジトリを設定し、containerd.ioパッケージをインストールする手順については、Getting started with containerdを参照してください。 -
containerdを設定する:
sudo mkdir -p /etc/containerd containerd config default | sudo tee /etc/containerd/config.toml -
containerdを再起動する:
sudo systemctl restart containerd
PowerShellセッションを開始し、$Versionに目的のバージョンを設定します(例: $Version="1.4.3")。
その後、次のコマンドを実行します:
-
containerdをダウンロードする:
curl.exe -L https://github.com/containerd/containerd/releases/download/v$Version/containerd-$Version-windows-amd64.tar.gz -o containerd-windows-amd64.tar.gz tar.exe xvf .\containerd-windows-amd64.tar.gz -
展開および設定:
Copy-Item -Path ".\bin\" -Destination "$Env:ProgramFiles\containerd" -Recurse -Force cd $Env:ProgramFiles\containerd\ .\containerd.exe config default | Out-File config.toml -Encoding ascii # 設定内容を確認します。セットアップによっては、以下を調整する必要があります: # - sandbox_image(Kubernetesのpauseイメージ) # - cniのbin_dirおよびconf_dirの場所 Get-Content config.toml # (オプションだが、強く推奨される)containerdをWindows Defenderのスキャン対象から除外する Add-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe" -
containerdを起動する:
.\containerd.exe --register-service Start-Service containerd
containerdをコンテナランタイムとして使用するためのkubeletの設定
/var/lib/kubelet/kubeadm-flags.envファイルを編集し、フラグに--container-runtime-endpoint=unix:///run/containerd/containerd.sockを追加して、containerdランタイムを指定します。
kubeadmを使用しているユーザーは、kubeadmツールが各ホストのCRIソケットを、そのホストのノードオブジェクトにアノテーションとして保存していることに注意してください。
これを変更するには、/etc/kubernetes/admin.confファイルが存在するマシン上で次のコマンドを実行します。
kubectl edit no <node-name>
これによりテキストエディタが起動し、ノードオブジェクトを編集できます。
使用するテキストエディタを指定するには、KUBE_EDITOR環境変数を設定してください。
-
kubeadm.alpha.kubernetes.io/cri-socketの値を/var/run/dockershim.sockから、使用したいCRIソケットのパス(例:unix:///run/containerd/containerd.sock)に変更します。新しいCRIソケットのパスは、原則として
unix://で始める必要がある点に注意してください。 -
テキストエディタで変更を保存すると、ノードオブジェクトが更新されます。
kubeletの再起動
systemctl start kubelet
ノードが正常であることの確認
kubectl get nodes -o wideを実行し、先ほど変更したノードのランタイムとしてcontainerdが表示されていることを確認します。
Docker Engineの削除
ノードが正常に見える場合は、Dockerを削除します。
sudo yum remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
sudo dnf remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
前述のコマンドは、ホスト上のイメージ、コンテナ、ボリューム、またはカスタマイズされた設定ファイルを削除しません。 これらを削除するには、DockerのDocker Engineのアンインストール手順に従ってください。
注意:
Docker Engineのアンインストール手順には、containerdを削除してしまうリスクがあります。コマンドの実行には十分注意してください。ノードのuncordon
kubectl uncordon <node-to-uncordon>
<node-to-uncordon>は、以前にドレインしたノードの名前に置き換えてください。
2.2 - ノードで使用されているコンテナランタイムの確認
このページでは、クラスター内のノードが使用しているコンテナランタイムを確認する手順を概説しています。
クラスターの実行方法によっては、ノード用のコンテナランタイムが事前に設定されている場合と、設定する必要がある場合があります。
マネージドKubernetesサービスを使用している場合、ノードに設定されているコンテナランタイムを確認するためのベンダー固有の方法があるかもしれません。
このページで説明する方法は、kubectlの実行が許可されていればいつでも動作するはずです。
始める前に
kubectlをインストールし、設定します。詳細はツールのインストールの項を参照してください。
ノードで使用されているコンテナランタイムの確認
ノードの情報を取得して表示するにはkubectlを使用します:
kubectl get nodes -o wide
出力は以下のようなものです。列CONTAINER-RUNTIMEには、ランタイムとそのバージョンが出力されます。
# For dockershim
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
# For containerd
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
コンテナランタイムについては、コンテナランタイムのページで詳細を確認することができます。
2.3 - dockershim削除の影響範囲を確認する
Kubernetesのdockershimコンポーネントは、DockerをKubernetesのコンテナランタイムとして使用することを可能にします。
Kubernetesの組み込みコンポーネントであるdockershimはリリースv1.24で削除されました。
このページでは、あなたのクラスターがどのようにDockerをコンテナランタイムとして使用しているか、使用中のdockershimが果たす役割について詳しく説明し、dockershimの削除によって影響を受けるワークロードがあるかどうかをチェックするためのステップを示します。
自分のアプリがDockerに依存しているかどうかの確認
アプリケーションコンテナの構築にDockerを使用している場合でも、これらのコンテナを任意のコンテナランタイム上で実行することができます。このようなDockerの使用は、コンテナランタイムとしてのDockerへの依存とはみなされません。
代替のコンテナランタイムが使用されている場合、Dockerコマンドを実行しても動作しないか、予期せぬ出力が得られる可能性があります。
このように、Dockerへの依存があるかどうかを調べることができます:
- 特権を持つPodがDockerコマンド(
docker psなど)を実行したり、Dockerサービスを再起動したり(systemctl restart docker.serviceなどのコマンド)、Docker固有のファイル(/etc/docker/daemon.jsonなど)を変更しないことを確認すること。 - Dockerの設定ファイル(
/etc/docker/daemon.jsonなど)にプライベートレジストリやイメージミラーの設定がないか確認します。これらは通常、別のコンテナランタイムのために再設定する必要があります。 - Kubernetesインフラストラクチャーの外側のノードで実行される以下のようなスクリプトやアプリがDockerコマンドを実行しないことを確認します。
- トラブルシューティングのために人間がノードにSSHで接続
- ノードのスタートアップスクリプト
- ノードに直接インストールされた監視エージェントやセキュリティエージェント
- 上記のような特権的な操作を行うサードパーティツール。詳しくはMigrating telemetry and security agents from dockershim を参照してください。
- dockershimの動作に間接的な依存性がないことを確認します。 これはエッジケースであり、あなたのアプリケーションに影響を与える可能性は低いです。ツールによっては、Docker固有の動作に反応するように設定されている場合があります。例えば、特定のメトリクスでアラートを上げたり、トラブルシューティングの指示の一部として特定のログメッセージを検索したりします。そのようなツールを設定している場合、移行前にテストクラスターで動作をテストしてください。
Dockerへの依存について解説
コンテナランタイムとは、Kubernetes Podを構成するコンテナを実行できるソフトウェアです。
KubernetesはPodのオーケストレーションとスケジューリングを担当し、各ノードではkubeletがコンテナランタイムインターフェースを抽象化して使用するので、互換性があればどのコンテナランタイムでも使用することができます。 初期のリリースでは、Kubernetesは1つのコンテナランタイムと互換性を提供していました: Dockerです。 その後、Kubernetesプロジェクトの歴史の中で、クラスター運用者は追加のコンテナランタイムを採用することを希望しました。 CRIはこのような柔軟性を可能にするために設計され、kubeletはCRIのサポートを開始しました。 しかし、DockerはCRI仕様が考案される前から存在していたため、Kubernetesプロジェクトはアダプタコンポーネント「dockershim」を作成しました。
dockershimアダプターは、DockerがCRI互換ランタイムであるかのように、kubeletがDockerと対話することを可能にします。 Kubernetes Containerd integration goes GAブログ記事で紹介されています。
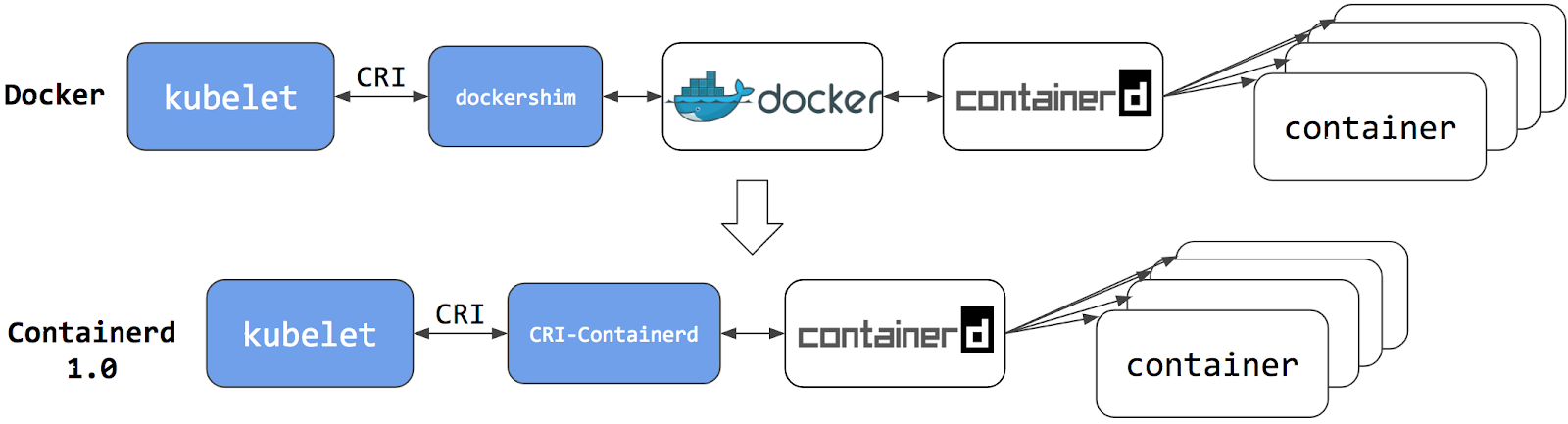
コンテナランタイムとしてContainerdに切り替えることで、中間マージンを排除することができます。
これまでと同じように、Containerdのようなコンテナランタイムですべてのコンテナを実行できます。
しかし今は、コンテナはコンテナランタイムで直接スケジュールするので、Dockerからは見えません。
そのため、これらのコンテナをチェックするために以前使っていたかもしれないDockerツールや派手なUIは、もはや利用できません。
docker psやdocker inspectを使用してコンテナ情報を取得することはできません。
コンテナを一覧表示できないので、ログを取得したり、コンテナを停止したり、docker execを使用してコンテナ内で何かを実行したりすることもできません。
備考:
Kubernetes経由でワークロードを実行している場合、コンテナを停止する最善の方法は、コンテナランタイムを直接経由するよりもKubernetes APIを経由することです(このアドバイスはDockerだけでなく、すべてのコンテナランタイムに適用されます)。この場合でも、イメージを取得したり、docker buildコマンドを使用してビルドすることは可能です。
しかし、Dockerによってビルドまたはプルされたイメージは、コンテナランタイムとKubernetesからは見えません。
Kubernetesで使用できるようにするには、何らかのレジストリにプッシュする必要がありました。
2.4 - dockershimからテレメトリーやセキュリティエージェントを移行する
Kubernetes 1.20でdockershimは非推奨になりました。
dockershimの削除に関するFAQから、ほとんどのアプリがコンテナをホストするランタイムに直接依存しないことは既にご存知かもしれません。 しかし、コンテナのメタデータやログ、メトリクスを収集するためにDockerに依存しているテレメトリーやセキュリティエージェントはまだ多く存在します。 この文書では、これらの依存関係を検出する方法と、これらのエージェントを汎用ツールまたは代替ランタイムに移行する方法に関するリンクを集約しています。
テレメトリーとセキュリティエージェント
Kubernetesクラスター上でエージェントを実行するには、いくつかの方法があります。エージェントはノード上で直接、またはDaemonSetとして実行することができます。
テレメトリーエージェントがDockerに依存する理由とは?
歴史的には、KubernetesはDockerの上に構築されていました。 Kubernetesはネットワークとスケジューリングを管理し、Dockerはコンテナをノードに配置して操作していました。 そのため、KubernetesからはPod名などのスケジューリング関連のメタデータを、Dockerからはコンテナの状態情報を取得することができます。 時が経つにつれ、コンテナを管理するためのランタイムも増えてきました。 また、多くのランタイムにまたがるコンテナ状態情報の抽出を一般化するプロジェクトやKubernetesの機能もあります。
いくつかのエージェントはDockerツールに関連しています。
エージェントはdocker psやdocker topといったコマンドを実行し、コンテナやプロセスの一覧を表示します。
またはdocker logsを使えば、dockerログを購読することができます。
Dockerがコンテナランタイムとして非推奨になったため、これらのコマンドはもう使えません。
Dockerに依存するDaemonSetの特定
Podがノード上で動作しているdockerdを呼び出したい場合、Podは以下のいずれかを行う必要があります。
-
Dockerデーモンの特権ソケットがあるファイルシステムをvolumeのようにマウントする。
-
Dockerデーモンの特権ソケットの特定のパスを直接ボリュームとしてマウントします。
例: COSイメージでは、DockerはそのUnixドメインソケットを/var/run/docker.sockに公開します。
つまり、Pod仕様には/var/run/docker.sockのhostPathボリュームマウントが含まれることになります。
以下は、Dockerソケットを直接マッピングしたマウントを持つPodを探すためのシェルスクリプトのサンプルです。
このスクリプトは、Podの名前空間と名前を出力します。
grep '/var/run/docker.sock'を削除して、他のマウントを確認することもできます。
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
備考:
Podがホスト上のDockerにアクセスするための代替方法があります。 例えば、フルパスの代わりに親ディレクトリ/var/runをマウントすることができます(この例 のように)。
上記のスクリプトは、最も一般的な使用方法のみを検出します。ノードエージェントからDockerの依存性を検出する
クラスターノードをカスタマイズし、セキュリティやテレメトリーのエージェントをノードに追加インストールする場合、エージェントのベンダーにDockerへの依存性があるかどうかを必ず確認してください。
テレメトリーとセキュリティエージェントのベンダー
様々なテレメトリーおよびセキュリティエージェントベンダーのための移行指示の作業中バージョンをGoogle docに保管しています。 dockershimからの移行に関する最新の手順については、各ベンダーにお問い合わせください。
3 - 証明書を手動で生成する
クライアント証明書認証を使用する場合、easyrsa、opensslまたはcfsslを使って手動で証明書を生成することができます。
easyrsa
easyrsaはクラスターの証明書を手動で生成することができます。
-
パッチが適用されたバージョンの
easyrsa3をダウンロードして解凍し、初期化します。curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
新しい認証局(CA)を生成します。
--batchで自動モードに設定します。--req-cnはCAの新しいルート証明書のコモンネーム(CN)を指定します。./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
サーバー証明書と鍵を生成します。
引数
--subject-alt-nameは、APIサーバーがアクセス可能なIPとDNS名を設定します。MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で--service-cluster-ip-range引数に指定したサービスCIDRの最初のIPとなります。 引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使用します。 また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。./easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyを自分のディレクトリにコピーします。 -
APIサーバーのスタートパラメーターに以下のパラメーターを記入し、追加します。
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
opensslは、クラスター用の証明書を手動で生成することができます。
-
2048bitのca.keyを生成します:
openssl genrsa -out ca.key 2048 -
ca.keyに従ってca.crtを生成します(
-daysで証明書の有効期限を設定します):openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
2048bitでserver.keyを生成します:
openssl genrsa -out server.key 2048 -
証明書署名要求(CSR)を生成するための設定ファイルを作成します。
山括弧で囲まれた値(例:
<MASTER_IP>)は必ず実際の値に置き換えてから、ファイル(例:csr.conf)に保存してください。MASTER_CLUSTER_IPの値は、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPであることに注意してください。また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
設定ファイルに基づき、証明書署名要求を生成します:
openssl req -new -key server.key -out server.csr -config csr.conf -
ca.key、ca.crt、server.csrを使用して、サーバー証明書を生成します:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -sha256 -
証明書署名要求を表示します:
openssl req -noout -text -in ./server.csr -
証明書を表示します:
openssl x509 -noout -text -in ./server.crt
最後に、同じパラメーターをAPIサーバーのスタートパラメーターに追加します。
cfssl
cfsslも証明書を生成するためのツールです。
-
以下のように、コマンドラインツールをダウンロードし、解凍して準備してください。
なお、サンプルのコマンドは、お使いのハードウェア・アーキテクチャやCFSSLのバージョンに合わせる必要があるかもしれません。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
成果物を格納するディレクトリを作成し、cfsslを初期化します:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
CAファイルを生成するためのJSON設定ファイル、例えば
ca-config.jsonを作成します:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
CA証明書署名要求(CSR)用のJSON設定ファイル(例:
ca-csr.json)を作成します。 山括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
CAキー(
ca-key.pem)と証明書(ca.pem)を生成します:../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル、例えば
server-csr.jsonを作成します。 山括弧内の値は、必ず使用したい実際の値に置き換えてください。MASTER_CLUSTER_IPは、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPです。 また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
APIサーバーの鍵と証明書を生成します。 デフォルトでは、それぞれ
server-key.pemとserver.pemというファイルに保存されます:../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
自己署名入りCA証明書を配布する
クライアントノードが自己署名入りCA証明書を有効なものとして認識できない場合があります。
非プロダクション環境、または会社のファイアウォールの内側での開発環境であれば、自己署名入りCA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新することができます。
各クライアントで、次の操作を実行します:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API
認証に使用するx509証明書のプロビジョニングにはcertificates.k8s.ioAPIを使用することができます。クラスターでのTLSの管理に記述されています。
4 - メモリー、CPU、APIリソースの管理
4.1 - ネームスペースのデフォルトのメモリー要求と制限を設定する
このページでは、ネームスペースのデフォルトのメモリー要求と制限を設定する方法を説明します。
Kubernetesクラスターはネームスペースに分割することができます。デフォルトのメモリー制限を持つネームスペースがあり、独自のメモリー制限を指定しないコンテナでPodを作成しようとすると、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を割り当てます。
Kubernetesは、このトピックで後ほど説明する特定の条件下で、デフォルトのメモリー要求を割り当てます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
クラスターにネームスペースを作成するには、アクセス権が必要です。
クラスターの各ノードには、最低でも2GiBのメモリーが必要です。
ネームスペースの作成
この演習で作成したリソースがクラスターの他の部分から分離されるように、ネームスペースを作成します。
kubectl create namespace default-mem-example
LimitRangeとPodの作成
以下は、LimitRangeのマニフェストの例です。このマニフェストでは、デフォルトのメモリー要求とデフォルトのメモリー制限を指定しています。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
default-mem-exampleネームスペースにLimitRangeを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
default-mem-exampleネームスペースでPodを作成し、そのPod内のコンテナがメモリー要求とメモリー制限の値を独自に指定しない場合、コントロールプレーンはデフォルト値のメモリー要求256MiBとメモリー制限512MiBを適用します。
以下は、コンテナを1つ持つPodのマニフェストの例です。コンテナは、メモリー要求とメモリー制限を指定していません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
この出力は、Podのコンテナのメモリー要求が256MiBで、メモリー制限が512MiBであることを示しています。 これらはLimitRangeで指定されたデフォルト値です。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
Podを削除します:
kubectl delete pod default-mem-demo --namespace=default-mem-example
コンテナの制限を指定し、要求を指定しない場合
以下は1つのコンテナを持つPodのマニフェストです。コンテナはメモリー制限を指定しますが、メモリー要求は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求がそのメモリー制限に一致するように設定されていることを示しています。 コンテナにはデフォルトのメモリー要求値である256Miが割り当てられていないことに注意してください。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナの要求を指定し、制限を指定しない場合
1つのコンテナを持つPodのマニフェストです。コンテナはメモリー要求を指定しますが、メモリー制限は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求が、コンテナのマニフェストで指定された値に設定されていることを示しています。 コンテナは512MiB以下のメモリーを使用するように制限されていて、これはネームスペースのデフォルトのメモリー制限と一致します。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
デフォルトのメモリー制限と要求の動機
ネームスペースにメモリーリソースクォータが設定されている場合、メモリー制限のデフォルト値を設定しておくと便利です。
以下はリソースクォータがネームスペースに課す制限のうちの2つです。
- ネームスペースで実行されるすべてのPodについて、Podとその各コンテナにメモリー制限を設ける必要があります(Pod内のすべてのコンテナに対してメモリー制限を指定すると、Kubernetesはそのコンテナの制限を合計することでPodレベルのメモリー制限を推測することができます)。
- メモリー制限は、当該Podがスケジュールされているノードのリソース予約を適用します。ネームスペース内のすべてのPodに対して予約されるメモリーの総量は、指定された制限を超えてはなりません。
- また、ネームスペース内のすべてのPodが実際に使用するメモリーの総量も、指定された制限を超えてはなりません。
LimitRangeの追加時:
コンテナを含む、そのネームスペース内のいずれかのPodが独自のメモリー制限を指定していない場合、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を適用し、メモリーのResourceQuotaによって制限されているネームスペース内でPodを実行できるようにします。
クリーンアップ
ネームスペースを削除します:
kubectl delete namespace default-mem-example
次の項目
クラスター管理者向け
アプリケーション開発者向け
4.2 - Namespaceに対する最小および最大メモリー制約の構成
このページでは、Namespaceで実行されるコンテナが使用するメモリーの最小値と最大値を設定する方法を説明します。 LimitRange で最小値と最大値のメモリー値を指定します。 PodがLimitRangeによって課される制約を満たさない場合、そのNamespaceではPodを作成できません。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
クラスター内の各ノードには、少なくとも1GiBのメモリーが必要です。
Namespaceの作成
この演習で作成したリソースがクラスターの他の部分から分離されるように、Namespaceを作成します。
kubectl create namespace constraints-mem-example
LimitRangeとPodを作成
LimitRangeの設定ファイルです。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
LimitRangeを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
LimitRangeの詳細情報を表示します。
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
出力されるのは、予想通りメモリー制約の最小値と最大値を示しています。 しかし、LimitRangeの設定ファイルでデフォルト値を指定していないにもかかわらず、 自動的に作成されていることに気づきます。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
constraints-mem-exampleNamespaceにコンテナが作成されるたびに、 Kubernetesは以下の手順を実行するようになっています。
-
コンテナが独自のメモリー要求と制限を指定しない場合は、デフォルトのメモリー要求と制限をコンテナに割り当てます。
-
コンテナに500MiB以上のメモリー要求があることを確認します。
-
コンテナのメモリー制限が1GiB以下であることを確認します。
以下は、1つのコンテナを持つPodの設定ファイルです。設定ファイルのコンテナ(containers)では、600MiBのメモリー要求と800MiBのメモリー制限が指定されています。これらはLimitRangeによって課される最小と最大のメモリー制約を満たしています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
Podの作成
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
Podのコンテナが実行されていることを確認します。
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
出力は、コンテナが600MiBのメモリ要求と800MiBのメモリー制限になっていることを示しています。これらはLimitRangeによって課される制約を満たしています。
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
Podを消します。
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
最大メモリ制約を超えるPodの作成の試み
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは800MiBのメモリー要求と1.5GiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
出力は、コンテナが大きすぎるメモリー制限を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
最低限のメモリ要求を満たさないPodの作成の試み
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは100MiBのメモリー要求と800MiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
出力は、コンテナが小さすぎるメモリー要求を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
メモリ要求や制限を指定しないPodの作成
これは、1つのコンテナを持つPodの設定ファイルです。コンテナはメモリー要求を指定しておらず、メモリー制限も指定していません。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
Podを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
出力を見ると、Podのコンテナのメモリ要求は1GiB、メモリー制限は1GiBであることがわかります。 コンテナはどのようにしてこれらの値を取得したのでしょうか?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeから与えられのです。 コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeからデフォルトのメモリー要求と制限が与えられたのです。
この時点で、コンテナは起動しているかもしれませんし、起動していないかもしれません。このタスクの前提条件は、ノードが少なくとも1GiBのメモリーを持っていることであることを思い出してください。それぞれのノードが1GiBのメモリーしか持っていない場合、どのノードにも1GiBのメモリー要求に対応するのに十分な割り当て可能なメモリーがありません。たまたま2GiBのメモリーを持つノードを使用しているのであれば、おそらく1GiBのメモリーリクエストに対応するのに十分なスペースを持っていることになります。
Podを削除します。
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
最小および最大メモリー制約の強制
LimitRangeによってNamespaceに課される最大および最小のメモリー制約は、Podが作成または更新されたときにのみ適用されます。LimitRangeを変更しても、以前に作成されたPodには影響しません。
最小・最大メモリー制約の動機
クラスター管理者としては、Podが使用できるメモリー量に制限を課したいと思うかもしれません。
例:
-
クラスター内の各ノードは2GBのメモリーを持っています。クラスター内のどのノードもその要求をサポートできないため、2GB以上のメモリーを要求するPodは受け入れたくありません。
-
クラスターは運用部門と開発部門で共有されています。 本番用のワークロードでは最大8GBのメモリーを消費しますが、開発用のワークロードでは512MBに制限したいとします。本番用と開発用に別々のNamespaceを作成し、それぞれのNamespaceにメモリー制限を適用します。
クリーンアップ
Namespaceを削除します。
kubectl delete namespace constraints-mem-example
次の項目
クラスター管理者向け
アプリケーション開発者向け
5 - 拡張リソースをNodeにアドバタイズする
このページでは、Nodeに対して拡張リソースを指定する方法を説明します。拡張リソースを利用すると、Kubernetesにとって未知のノードレベルのリソースをクラスター管理者がアドバタイズできるようになります。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Nodeの名前を取得する
kubectl get nodes
この練習で使いたいNodeを1つ選んでください。
Nodeの1つで新しい拡張リソースをアドバタイズする
Node上の新しい拡張リソースをアドバタイズするには、HTTPのPATCHリクエストをKubernetes APIサーバーに送ります。たとえば、Nodeの1つに4つのドングルが接続されているとします。以下に、4つのドングルリソースをNodeにアドバタイズするPATCHリクエストの例を示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
Kubernetesは、ドングルとは何かも、ドングルが何に利用できるのかを知る必要もないことに注意してください。上のPATCHリクエストは、ただNodeが4つのドングルと呼ばれるものを持っているとKubernetesに教えているだけです。
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
kubectl proxy
もう1つのコマンドウィンドウを開き、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
備考:
上のリクエストにある~1は、PATCHのパスにおける/という文字をエンコーディングしたものです。JSON-Patch内のoperationのpathはJSON-Pointerとして解釈されます。詳細については、IETF RFC 6901のsection 3を読んでください。出力には、Nodeがキャパシティー4のdongleを持っていることが示されます。
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
Nodeの説明を確認します。
kubectl describe node <選択したNodeの名前>
出力には、再びdongleリソースが表示されます。
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
これで、アプリケーション開発者は特定の数のdongleをリクエストするPodを作成できるようになりました。詳しくは、拡張リソースをコンテナに割り当てるを読んでください。
議論
拡張リソースは、メモリやCPUリソースと同様のものです。たとえば、Nodeが持っている特定の量のメモリやCPUがNode上で動作している他のすべてのコンポーネントと共有されるのと同様に、Nodeが搭載している特定の数のdongleが他のすべてのコンポーネントと共有されます。そして、アプリケーション開発者が特定の量のメモリとCPUをリクエストするPodを作成できるのと同様に、Nodeが搭載している特定の数のdongleをリクエストするPodが作成できます。
拡張リソースはKubernetesには詳細を意図的に公開しないため、Kubernetesは拡張リソースの実体をまったく知りません。Kubernetesが知っているのは、Nodeが特定の数の拡張リソースを持っているということだけです。拡張リソースは整数値でアドバタイズしなければなりません。たとえば、Nodeは4つのdongleをアドバタイズできますが、4.5のdongleというのはアドバタイズできません。
Storageの例
Nodeに800GiBの特殊なディスクストレージがあるとします。この特殊なストレージの名前、たとえばexample.com/special-storageという名前の拡張リソースが作れます。そして、そのなかの一定のサイズ、たとえば100GiBのチャンクをアドバタイズできます。この場合、Nodeはexample.com/special-storageという種類のキャパシティ8のリソースを持っているとアドバタイズします。
Capacity:
...
example.com/special-storage: 8
特殊なストレージに任意のサイズのリクエストを許可したい場合、特殊なストレージを1バイトのサイズのチャンクでアドバタイズできます。その場合、example.com/special-storageという種類の800Giのリソースとしてアドバタイズします。
Capacity:
...
example.com/special-storage: 800Gi
すると、コンテナは好きなバイト数の特殊なストレージを最大800Giまでリクエストできるようになります。
クリーンアップ
以下に、dongleのアドバタイズをNodeから削除するPATCHリクエストを示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
kubectl proxy
もう1つのコマンドウィンドウで、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
dongleのアドバタイズが削除されたことを検証します。
kubectl describe node <選択したNodeの名前> | grep dongle
(出力には何も表示されないはずです)
次の項目
アプリケーション開発者向け
クラスター管理者向け
6 - クラウドコントローラーマネージャーの運用管理
Kubernetes v1.11 [beta]
クラウドプロバイダーはKubernetesプロジェクトとは異なるペースで開発およびリリースされるため、プロバイダー固有のコードを`cloud-controller-manager`バイナリに抽象化することでクラウドベンダーはKubernetesのコアのコードとは独立して開発が可能となりました。
cloud-controller-managerは、cloudprovider.Interfaceを満たす任意のクラウドプロバイダーと接続できます。下位互換性のためにKubernetesのコアプロジェクトで提供されるcloud-controller-managerはkube-controller-managerと同じクラウドライブラリを使用します。Kubernetesのコアリポジトリですでにサポートされているクラウドプロバイダーは、Kubernetesリポジトリにあるcloud-controller-managerを使用してKubernetesのコアから移行することが期待されています。
運用
要件
すべてのクラウドには動作させるためにそれぞれのクラウドプロバイダーの統合を行う独自の要件があり、kube-controller-managerを実行する場合の要件とそれほど違わないようにする必要があります。一般的な経験則として、以下のものが必要です。
- クラウドの認証/認可: クラウドではAPIへのアクセスを許可するためにトークンまたはIAMルールが必要になる場合があります
- kubernetesの認証/認可: cloud-controller-managerは、kubernetes apiserverと通信するためにRBACルールの設定を必要とする場合があります
- 高可用性: kube-controller-managerのように、リーダー選出を使用したクラウドコントローラーマネージャーの高可用性のセットアップが必要になる場合があります(デフォルトでオンになっています)。
cloud-controller-managerを動かす
cloud-controller-managerを正常に実行するにはクラスター構成にいくつかの変更が必要です。
kube-apiserverとkube-controller-managerは**--cloud-providerフラグを指定してはいけません**。これによりクラウドコントローラーマネージャーによって実行されるクラウド固有のループが実行されなくなります。将来このフラグは非推奨になり削除される予定です。kubeletは--cloud-provider=externalで実行する必要があります。これは作業をスケジュールする前にクラウドコントローラーマネージャーによって初期化する必要があることをkubeletが認識できるようにするためです。
クラウドコントローラーマネージャーを使用するようにクラスターを設定するとクラスターの動作がいくつか変わることに注意してください。
--cloud-provider=externalを指定したkubeletは、初期化時にNoScheduleのnode.cloudprovider.kubernetes.io/uninitialized汚染を追加します。これによりノードは作業をスケジュールする前に外部のコントローラーからの2回目の初期化が必要であるとマークされます。クラウドコントローラーマネージャーが使用できない場合クラスター内の新しいノードはスケジュールできないままになることに注意してください。スケジューラーはリージョンやタイプ(高CPU、GPU、高メモリ、スポットインスタンスなど)などのノードに関するクラウド固有の情報を必要とする場合があるためこの汚染は重要です。- クラスター内のノードに関するクラウド情報はローカルメタデータを使用して取得されなくなりましたが、代わりにノード情報を取得するためのすべてのAPI呼び出しはクラウドコントローラーマネージャーを経由して行われるようになります。これはセキュリティを向上させるためにkubeletでクラウドAPIへのアクセスを制限できることを意味します。大規模なクラスターではクラスター内からクラウドのほとんどすべてのAPI呼び出しを行うため、クラウドコントローラーマネージャーがレートリミットに達するかどうかを検討する必要があります。
クラウドコントローラーマネージャーは以下を実装できます。
- ノードコントローラー - クラウドAPIを使用してkubernetesノードを更新し、クラウドで削除されたkubernetesノードを削除します。
- サービスコントローラー - タイプLoadBalancerのサービスに対応してクラウド上のロードバランサーを操作します。
- ルートコントローラー - クラウド上でネットワークルートを設定します。
- Kubernetesリポジトリの外部にあるプロバイダーを実行している場合はその他の機能の実装。
例
現在Kubernetesのコアでサポートされているクラウドを使用していて、クラウドコントローラーマネージャーを利用する場合は、kubernetesのコアのクラウドコントローラーマネージャーを参照してください。
Kubernetesのコアリポジトリにないクラウドコントローラーマネージャーの場合、クラウドベンダーまたはsigリードが管理するリポジトリでプロジェクトを見つけることができます。
すでにKubernetesのコアリポジトリにあるプロバイダーの場合、クラスター内でデーモンセットとしてKubernetesリポジトリ内部のクラウドコントローラーマネージャーを実行できます。以下をガイドラインとして使用してください。
# This is an example of how to set up cloud-controller-manager as a Daemonset in your cluster.
# It assumes that your masters can run pods and has the role node-role.kubernetes.io/master
# Note that this Daemonset will not work straight out of the box for your cloud, this is
# meant to be a guideline.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# for in-tree providers we use registry.k8s.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image: registry.k8s.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# this is required so CCM can bootstrap itself
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector:
node-role.kubernetes.io/master: ""
制限
クラウドコントローラーマネージャーの実行にはいくつかの制限があります。これらの制限は今後のリリースで対処されますが、本番のワークロードにおいてはこれらの制限を認識することが重要です。
ボリュームのサポート
ボリュームの統合にはkubeletとの調整も必要になるためクラウドコントローラーマネージャーはkube-controller-managerにあるボリュームコントローラーを実装しません。CSI(コンテナストレージインターフェース)が進化してFlexボリュームプラグインの強力なサポートが追加されるにつれ、クラウドがボリュームと完全に統合できるようクラウドコントローラーマネージャーに必要なサポートが追加されます。Kubernetesリポジトリの外部にあるCSIボリュームプラグインの詳細についてはこちらをご覧ください。
スケーラビリティ
cloud-controller-managerは、クラウドプロバイダーのAPIにクエリーを送信して、すべてのノードの情報を取得します。非常に大きなクラスターの場合、リソース要件やAPIレートリミットなどのボトルネックの可能性を考慮する必要があります。
鶏と卵
クラウドコントローラーマネージャープロジェクトの目標はKubernetesのコアプロジェクトからクラウドに関する機能の開発を切り離すことです。残念ながら、Kubernetesプロジェクトの多くの面でクラウドプロバイダーの機能がKubernetesプロジェクトに緊密に結びついているという前提があります。そのため、この新しいアーキテクチャを採用するとクラウドプロバイダーの情報を要求する状況が発生する可能性がありますが、クラウドコントローラーマネージャーはクラウドプロバイダーへのリクエストが完了するまでその情報を返すことができない場合があります。
これの良い例は、KubeletのTLSブートストラップ機能です。TLSブートストラップはKubeletがすべてのアドレスタイプ(プライベート、パブリックなど)をクラウドプロバイダー(またはローカルメタデータサービス)に要求する能力を持っていると仮定していますが、クラウドコントローラーマネージャーは最初に初期化されない限りノードのアドレスタイプを設定できないためapiserverと通信するためにはkubeletにTLS証明書が必要です。
このイニシアチブが成熟するに連れ、今後のリリースでこれらの問題に対処するための変更が行われます。
次の項目
独自のクラウドコントローラーマネージャーを構築および開発するにはクラウドコントローラーマネージャーの開発を参照してください。
7 - kubelet image credential providerの設定
Kubernetes v1.26 [stable]
Kubernetes v1.20以降、kubeletはexecプラグインを使用してコンテナイメージレジストリへの認証情報を動的に取得できるようになりました。 kubeletとexecプラグインは、Kubernetesのバージョン管理されたAPIを用いて標準入出力(stdin、stdout、stderr)を通じて通信します。 これらのプラグインを使用することで、kubeletはディスク上に静的な認証情報を保存する代わりに、コンテナレジストリへの認証情報を動的に要求できるようになります。 たとえば、プラグインがローカルのメタデータサーバーと通信し、kubeletが取得しようとしているイメージに対する、短期間有効な認証情報を取得することがあります。
以下のいずれかに該当する場合、この機能の利用を検討するとよいでしょう:
- レジストリへの認証情報を取得するために、クラウドプロバイダーのサービスへのAPI呼び出しが必要である。
- 認証情報の有効期限が短く、頻繁に新しい認証情報の取得が必要である。
- 認証情報をディスク上やimagePullSecretsに保存することが許容されない。
このガイドでは、kubelet image credential providerプラグイン機構の設定方法について説明します。
イメージ取得用のServiceAccountトークン
Kubernetes v1.34 [beta](enabled by default)Kubernetes v1.33以降、kubeletは、イメージの取得を行っているPodにバインドされたサービスアカウントトークンを、credential providerプラグインに送信するように設定できます。
これにより、プラグインはそのトークンを使用して、イメージレジストリへのアクセスに必要な認証情報と交換することが可能になります。
この機能を有効化するには、kubeletでKubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートを有効化し、プラグイン用のCredentialProviderConfigファイルでtokenAttributesフィールドを設定する必要があります。
tokenAttributesフィールドには、プラグインに渡されるサービスアカウントトークンに関する情報が含まれており、トークンの対象となるオーディエンスや、プラグインがPodにサービスアカウントを必要とするかどうかといった内容が指定されます。
サービスアカウントトークンによる認証情報を用いることで、次のようなユースケースに対応できます:
- レジストリからイメージを取得するために、kubeletやノードに基づくアイデンティティを必要としないようにする
- 長期間有効なシークレットや永続的なシークレットを使用せずに、ワークロードが自身のランタイムのアイデンティティに基づいてイメージを取得できるようにする
始める前に
- kubelet credential providerプラグインをサポートするノードを持つKubernetesクラスターが必要です。このサポートは、Kubernetes 1.34で利用可能です。Kubernetes v1.24およびv1.25で、デフォルトで有効なベータ機能として含まれるようになりました。
- サービスアカウントトークンを必要とするcredential providerプラグインを設定する場合は、Kubernetes v1.33以降を実行しているノードを持つクラスターと、kubelet上で
KubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートが有効になっている必要があります。 - credential provider execプラグインの動作する実装。独自にプラグインを作成するか、クラウドプロバイダーが提供するものを使用できます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ノードへのプラグインのインストール
credential providerプラグインは、kubeletによって実行される実行可能バイナリです。 クラスター内のすべてのノードにこのプラグインバイナリが存在し、既知のディレクトリに配置されていることを確認してください。 このディレクトリは、後でkubeletのフラグを設定する際に必要です。
kubeletの設定
この機能を使用するには、kubeletに次の2つのフラグを設定する必要があります:
--image-credential-provider-config- credential providerプラグインの設定ファイルへのパス--image-credential-provider-bin-dir- credential providerプラグインのバイナリが配置されているディレクトリへのパス
kubelet credential providerを設定する
--image-credential-provider-configに指定された設定ファイルは、どのコンテナイメージに対してどのexecプラグインを呼び出すかを判断するためにkubeletによって読み込まれます。
以下は、ECRベースのプラグインを使用する場合に利用される可能性がある設定ファイルの例です。
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
# providersは、kubeletによって有効化されるcredential provider補助プラグインのリストです。
# 単一のイメージに対して複数のプロバイダーが一致する場合、すべてのプロバイダーからの認証情報がkubeletに返されます。
# 単一のイメージに対して複数のプロバイダーが呼び出されると、結果は結合されます。
# 認証キーが重複する場合は、このリスト内で先に定義されたプロバイダーの値が使用されます。
providers:
# nameはcredential providerの名前で必須項目です。kubeletから見えるプロバイダーの実行可能ファイル名と一致している必要があります。
# 実行可能ファイルは、kubeletのbinディレクトリ(--image-credential-provider-bin-dirフラグで指定)内に存在しなければなりません。
- name: ecr-credential-provider
# matchImagesは必須の文字列リストで、イメージに対して一致判定を行い、
# このプロバイダーを呼び出すべきかどうかを判断するために使用されます。
# 指定された文字列のいずれか1つが、kubeletから要求されたイメージに一致した場合、
# プラグインが呼び出され、認証情報を提供する機会が与えられます。
# イメージには、レジストリのドメインおよびURLパスが含まれている必要があります。
#
# matchImagesの各エントリは、オプションでポートおよびパスを含むことができるパターンです。
# ドメインにはグロブを使用できますが、ポートやパスには使用できません。
# グロブは、'*.k8s.io'や'k8s.*.io'のようなサブドメインや、'k8s.*'のようなトップレベルドメインでサポートされています。
# 'app*.k8s.io'のような部分的なサブドメインの一致もサポートされています。
# 各グロブはサブドメインの1セグメントのみに一致するため、`*.io`は`*.k8s.io`には**一致しません**。
#
# イメージとmatchImageが一致すると見なされるのは、以下のすべての条件を満たす場合です:
# - 双方が同じ数のドメインパートを含み、各パートが一致していること
# - matchImagesに指定されたURLパスが、対象のイメージURLパスのプレフィックスであること
# - matchImagesにポートが含まれている場合、そのポートがイメージのポートにも一致すること
#
# matchImagesの値の例:
# - 123456789.dkr.ecr.us-east-1.amazonaws.com
# - *.azurecr.io
# - gcr.io
# - *.*.registry.io
# - registry.io:8080/path
matchImages:
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
# defaultCacheDurationは、プラグインの応答にキャッシュ期間が指定されていない場合に、
# プラグインが認証情報をメモリ内でキャッシュするデフォルトの期間です。このフィールドは必須です。
defaultCacheDuration: "12h"
# exec CredentialProviderRequestの入力に必要なバージョンです。返されるCredentialProviderResponseは、
# 入力と同じエンコーディングバージョンを使用しなければなりません。現在サポートされている値は以下のとおりです:
# - credentialprovider.kubelet.k8s.io/v1
apiVersion: credentialprovider.kubelet.k8s.io/v1
# コマンドを実行する際に渡す引数です。
# +optional
# args:
# - --example-argument
# envは、プロセスに対して公開する追加の環境変数を定義します。
# これらはホストの環境変数および、client-goがプラグインに引数を渡すために使用する変数と結合されます。
# +optional
env:
- name: AWS_PROFILE
value: example_profile
# tokenAttributesは、プラグインに渡されるサービスアカウントトークンの設定です。
# このフィールドを設定することで、credential providerはイメージの取得にサービスアカウントトークンを使用するようになります。
# このフィールドが設定されているにも関わらず、`KubeletServiceAccountTokenForCredentialProviders`フィーチャーゲートが有効になっていない場合、
# kubeletは無効な設定エラーとして起動に失敗します。
# +optional
tokenAttributes:
# serviceAccountTokenAudienceは、投影されたサービスアカウントトークンの対象となるオーディエンスです。
# +required
serviceAccountTokenAudience: "<audience for the token>"
# requireServiceAccountは、プラグインがPodにサービスアカウントを必要とするかどうかを示します。
# trueに設定された場合、kubeletはPodにサービスアカウントがある場合にのみプラグインを呼び出します。
# falseに設定された場合、Podにサービスアカウントがなくてもkubeletはプラグインを呼び出し、
# CredentialProviderRequestにはトークンを含めません。これは、サービスアカウントを持たないPod
# (たとえば、Static Pod)に対してイメージを取得するためのプラグインに有用です。
# +required
requireServiceAccount: true
# requiredServiceAccountAnnotationKeysは、プラグインが対象とし、サービスアカウントに存在する必要があるアノテーションキーのリストです。
# このリストに定義されたキーは、対応するサービスアカウントから抽出され、CredentialProviderRequestの一部としてプラグインに渡されます。
# このリストに定義されたキーのいずれかがサービスアカウントに存在しない場合、kubeletはプラグインを呼び出さず、エラーを返します。
# このフィールドはオプションであり、空であっても構いません。プラグインはこのフィールドを使用して、
# 認証情報の取得に必要な追加情報を抽出したり、サービスアカウントトークンによるイメージ取得の利用を
# ワークロード側で選択可能にしたりできます。
# このフィールドが空でない場合、requireServiceAccountはtrueに設定されていなければなりません。
# このリストに定義されたキーは一意である必要があり、
# optionalServiceAccountAnnotationKeysリストに定義されたキーと重複してはいけません。
# +optional
requiredServiceAccountAnnotationKeys:
- "example.com/required-annotation-key-1"
- "example.com/required-annotation-key-2"
# optionalServiceAccountAnnotationKeysは、プラグインが対象とするアノテーションキーのリストで、
# サービスアカウントに存在していなくてもよいオプションの項目です。
# このリストに定義されたキーは、対応するサービスアカウントから抽出され、
# CredentialProviderRequestの一部としてプラグインに渡されます。
# アノテーションの存在や値の検証はプラグイン側の責任です。
# このフィールドはオプションであり、空でも構いません。
# プラグインはこのフィールドを使用して、認証情報の取得に必要な追加情報を抽出できます。
# このリストに定義されたキーは一意でなければならず、
# requiredServiceAccountAnnotationKeysリストに定義されたキーと重複してはいけません。
# +optional
optionalServiceAccountAnnotationKeys:
- "example.com/optional-annotation-key-1"
- "example.com/optional-annotation-key-2"
providersフィールドは、kubeletが使用する有効なプラグインのリストです。
各エントリには、いくつかの入力必須のフィールドがあります:
name: プラグインの名前であり、--image-credential-provider-bin-dirで指定されたディレクトリ内に存在する実行可能バイナリの名前と一致していなければなりません。matchImages: このプロバイダーを呼び出すべきかどうかを判断するために、イメージと照合するための文字列リスト。詳細は後述します。defaultCacheDuration: プラグインによってキャッシュ期間が指定されていない場合に、kubeletが認証情報をメモリ内にキャッシュするデフォルトの期間。apiVersion: kubeletとexecプラグインが通信時に使用するAPIバージョン。
各credential providerには、オプションの引数や環境変数を指定することもできます。 特定のプラグインで必要となる引数や環境変数のセットについては、プラグインの実装者に確認してください。
KubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートを使用し、tokenAttributesフィールドを設定してプラグインにサービスアカウントトークンを使用させる場合、以下のフィールドの設定が必須となります:
-
serviceAccountTokenAudience: 投影されたサービスアカウントトークンの対象となるオーディエンス。 空文字列は指定できません。 -
requireServiceAccount: プラグインがPodにサービスアカウントを必要とするかどうか。trueに設定すると、Podにサービスアカウントがある場合にのみkubeletはプラグインを呼び出します。falseに設定すると、Podにサービスアカウントがなくてもkubeletはプラグインを呼び出し、CredentialProviderRequestにはトークンを含めません。
これは、サービスアカウントを持たないPod(たとえば、Static Pod)に対してイメージを取得するためのプラグインに有用です。
イメージのマッチングを設定する
各credential providerのmatchImagesフィールドは、Podが使用する特定のイメージに対してプラグインを呼び出すべきかどうかを、kubeletが判断するために使用されます。
matchImagesの各エントリはイメージパターンであり、オプションでポートやパスを含めることができます。
ドメインにはグロブを使用できますが、ポートやパスには使用できません。
グロブは、*.k8s.ioやk8s.*.ioのようなサブドメインや、k8s.*のようなトップレベルドメインで使用可能です。
app*.k8s.ioのような部分的なサブドメインの一致もサポートされています。
ただし、各グロブは1つのサブドメインセグメントにしか一致しないため、*.ioは*.k8s.ioには一致しません。
イメージ名とmatchImageエントリが一致すると見なされるのは、以下のすべての条件を満たす場合です:
- 両者が同じ数のドメインパートを持ち、それぞれのパートが一致していること。
- イメージの一致条件として指定されたURLパスが、対象のイメージのURLパスのプレフィックスであること。
- matchImagesにポートが含まれている場合、イメージのポートとも一致すること。
matchImagesパターンの値のいくつかの例:
123456789.dkr.ecr.us-east-1.amazonaws.com*.azurecr.iogcr.io*.*.registry.iofoo.registry.io:8080/path
次の項目
CredentialProviderConfigの詳細については、kubelet設定API(v1)リファレンスを参照してください。- kubelet credential provider APIリファレンス(v1)を参照してください。
8 - ノードのトポロジー管理ポリシーを制御する
Kubernetes v1.18 [beta]
近年、CPUやハードウェア・アクセラレーターの組み合わせによって、レイテンシーが致命的となる実行や高いスループットを求められる並列計算をサポートするシステムが増えています。このようなシステムには、通信、科学技術計算、機械学習、金融サービス、データ分析などの分野のワークロードが含まれます。このようなハイブリッドシステムは、高い性能の環境で構成されます。
最高のパフォーマンスを引き出すために、CPUの分離やメモリーおよびデバイスの位置に関する最適化が求められます。しかしながら、Kubernetesでは、これらの最適化は分断されたコンポーネントによって処理されます。
トポロジーマネージャー はKubeletコンポーネントの1つで最適化の役割を担い、コンポーネント群を調和して機能させます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.18.バージョンを確認するには次のコマンドを実行してください: kubectl version.
トポロジーマネージャーはどのように機能するか
トポロジーマネージャー導入前は、KubernetesにおいてCPUマネージャーやデバイスマネージャーはそれぞれ独立してリソースの割り当てを決定します。 これは、マルチソケットのシステムでは望ましくない割り当てとなり、パフォーマンスやレイテンシーが求められるアプリケーションは、この望ましくない割り当てに悩まされます。 この場合の望ましくない例として、CPUやデバイスが異なるNUMAノードに割り当てられ、それによりレイテンシー悪化を招くことが挙げられます。
トポロジーマネージャーはKubeletコンポーネントであり、信頼できる情報源として振舞います。それによって、他のKubeletコンポーネントはトポロジーに沿ったリソース割り当ての選択を行うことができます。
トポロジーマネージャーは Hint Providers と呼ばれるコンポーネントのインターフェースを提供し、トポロジー情報を送受信します。トポロジーマネージャーは、ノード単位のポリシー群を保持します。ポリシーについて以下で説明します。
トポロジーマネージャーは Hint Providers からトポロジー情報を受け取ります。トポロジー情報は、利用可能なNUMAノードと優先割り当て表示を示すビットマスクです。トポロジーマネージャーのポリシーは、提供されたヒントに対して一連の操作を行い、ポリシーに沿ってヒントをまとめて最適な結果を得ます。もし、望ましくないヒントが保存された場合、ヒントの優先フィールドがfalseに設定されます。現在のポリシーでは、最も狭い優先マスクが優先されます。
選択されたヒントはトポロジーマネージャーの一部として保存されます。設定されたポリシーにしたがい、選択されたヒントに基づいてノードがPodを許可したり、拒否することができます。 トポロジーマネージャーに保存されたヒントは、Hint Providers が使用しリソース割り当てを決定します。
トポロジーマネージャーの機能を有効にする
トポロジーマネージャーをサポートするには、TopologyManager フィーチャーゲートを有効にする必要があります。Kubernetes 1.18ではデフォルトで有効です。
トポロジーマネージャーのスコープとポリシー
トポロジーマネージャは現在:
- 全てのQoAクラスのPodを調整する
- Hint Providerによって提供されたトポロジーヒントから、要求されたリソースを調整する
これらの条件が合致した場合、トポロジーマネージャーは要求されたリソースを調整します。
この調整をどのように実行するかカスタマイズするために、トポロジーマネージャーは2つのノブを提供します: スコープ とポリシーです。
スコープはリソースの配置を行う粒度を定義します(例:podやcontainer)。そして、ポリシーは調整を実行するための実戦略を定義します(best-effort, restricted, single-numa-node等)。
現在利用可能なスコープとポリシーの値について詳細は以下の通りです。
備考:
PodのSpecにある他の要求リソースとCPUリソースを調整するために、CPUマネージャーを有効にし、適切なCPUマネージャーのポリシーがノードに設定されるべきです。CPU管理ポリシーを参照してください。備考:
PodのSpecにある他の要求リソースとメモリー(およびhugepage)リソースを調整するために、メモリーマネージャーを有効にし、適切なメモリーマネージャーポリシーがノードに設定されるべきです。メモリーマネージャー のドキュメントを確認してください。トポロジーマネージャーのスコープ
トポロジーマネージャーは、以下の複数の異なるスコープでリソースの調整を行う事が可能です:
container(デフォルト)pod
いずれのオプションも、--topology-manager-scopeフラグによって、kubelet起動時に選択できます。
containerスコープ
containerスコープはデフォルトで使用されます。
このスコープでは、トポロジーマネージャーは連続した複数のリソース調整を実行します。つまり、Pod内の各コンテナは、分離された配置計算がされます。言い換えると、このスコープでは、コンテナを特定のNUMAノードのセットにグループ化するという概念はありません。実際には、トポロジーマネージャーは各コンテナのNUMAノードへの配置を任意に実行します。
コンテナをグループ化するという概念は、以下のスコープで設定・実行されます。例えば、podスコープが挙げられます。
podスコープ
podスコープを選択するには、コマンドラインで--topology-manager-scope=podオプションを指定してkubeletを起動します。
このスコープでは、Pod内全てのコンテナを共通のNUMAノードのセットにグループ化することができます。トポロジーマネージャーはPodをまとめて1つとして扱い、ポッド全体(全てのコンテナ)を単一のNUMAノードまたはNUMAノードの共通セットのいずれかに割り当てようとします。以下の例は、さまざまな場面でトポロジーマネージャーが実行する調整を示します:
- 全てのコンテナは、単一のNUMAノードに割り当てられます。
- 全てのコンテナは、共有されたNUMAノードのセットに割り当てられます。
Pod全体に要求される特定のリソースの総量は有効なリクエスト/リミットの式に従って計算されるため、この総量の値は以下の最大値となります。
- 全てのアプリケーションコンテナのリクエストの合計。
- リソースに対するinitコンテナのリクエストの最大値。
podスコープとsingle-numa-nodeトポロジーマネージャーポリシーを併用することは、レイテンシーが重要なワークロードやIPCを行う高スループットのアプリケーションに対して特に有効です。両方のオプションを組み合わせることで、Pod内の全てのコンテナを単一のNUMAノードに配置できます。そのため、PodのNUMA間通信によるオーバーヘッドを排除することができます。
single-numa-nodeポリシーの場合、可能な割り当ての中に適切なNUMAノードのセットが存在する場合にのみ、Podが許可されます。上の例をもう一度考えてみましょう:
- 1つのNUMAノードのみを含むセット - Podが許可されます。
- 2つ以上のNUMAノードを含むセット - Podが拒否されます(1つのNUMAノードの代わりに、割り当てを満たすために2つ以上のNUMAノードが必要となるため)。
要約すると、トポロジーマネージャーはまずNUMAノードのセットを計算し、それをトポロジーマネージャーのポリシーと照合し、Podの拒否または許可を検証します。
トポロジーマネージャーのポリシー
トポロジーマネージャーは4つの調整ポリシーをサポートします。--topology-manager-policyというKubeletフラグを通してポリシーを設定できます。
4つのサポートされるポリシーがあります:
none(デフォルト)best-effortrestrictedsingle-numa-node
備考:
トポロジーマネージャーが pod スコープで設定された場合、コンテナはポリシーによって、Pod全体の要求として反映します。 したがって、Podの各コンテナは 同じ トポロジー調整と同じ結果となります。none ポリシー
これはデフォルトのポリシーで、トポロジーの調整を実行しません。
best-effort ポリシー
Pod内の各コンテナに対して、best-effort トポロジー管理ポリシーが設定されたkubeletは、各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはこれを保存し、Podをノードに許可します。
Hint Providers はこの情報を使ってリソースの割り当てを決定します。
restricted ポリシー
Pod内の各コンテナに対して、restricted トポロジー管理ポリシーが設定されたkubeletは各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはPodをそのノードに割り当てることを拒否します。この結果、PodはPodの受付失敗となりTerminated 状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試み ません 。Podの再デプロイをするためには、ReplicasetかDeploymenを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podが許可されれば、 Hint Providers はこの情報を使ってリソースの割り当てを決定します。
single-numa-node ポリシー
Pod内の各コンテナに対して、single-numa-nodeトポロジー管理ポリシーが設定されたkubeletは各Hint Prociderを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、単一のNUMAノードアフィニティが可能かどうか決定します。
可能な場合、トポロジーマネージャーは、この情報を保存し、Hint Providers はこの情報を使ってリソースの割り当てを決定します。
不可能な場合、トポロジーマネージャーは、Podをそのノードに割り当てることを拒否します。この結果、Pod は Pod の受付失敗となりTerminated状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試みません。Podの再デプロイをするためには、ReplicasetかDeploymentを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podとトポロジー管理ポリシーの関係
以下のようなpodのSpecで定義されるコンテナを考えます:
spec:
containers:
- name: nginx
image: nginx
requestsもlimitsも定義されていないため、このPodはBestEffortQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
requestsがlimitsより小さい値のため、このPodはBurstableQoSクラスで実行します。
選択されたポリシーがnone以外の場合、トポロジーマネージャーは、これらのPodのSpecを考慮します。トポロジーマネージャーは、Hint Providersからトポロジーヒントを取得します。CPUマネージャーポリシーがstaticの場合、デフォルトのトポロジーヒントを返却します。これらのPodは明示的にCPUリソースを要求していないからです。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
整数値でCPUリクエストを指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
CPUの一部をリクエストで指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
CPUもメモリもリクエスト値がないため、このPodは BestEffort QoSクラスで実行します。
トポロジーマネージャーは、上記Podを考慮します。トポロジーマネージャーは、Hint ProvidersとなるCPUマネージャーとデバイスマネージャーに問い合わせ、トポロジーヒントを取得します。
整数値でCPU要求を指定されたGuaranteedQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、排他的なCPUに関するトポロジーヒントを返却し、デバイスマネージャーは要求されたデバイスのヒントを返します。
CPUの一部を要求を指定されたGuaranteedQoSクラスのPodの場合、排他的ではないCPU要求のためstaticが設定されたCPUマネージャーポリシーはデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスのヒントを返します。
上記のGuaranteedQoSクラスのPodに関する2ケースでは、noneで設定されたCPUマネージャーポリシーは、デフォルトのトポロジーヒントを返却します。
BestEffortQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、CPUの要求がないためデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスごとのヒントを返します。
トポロジーマネージャーはこの情報を使用してPodに最適なヒントを計算し保存します。保存されたヒントは Hint Providersが使用しリソースを割り当てます。
既知の制限
-
トポロジーマネージャーが許容するNUMAノードの最大値は8です。8より多いNUMAノードでは、可能なNUMAアフィニティを列挙しヒントを生成する際に、生成する状態数が爆発的に増加します。
-
スケジューラーはトポロジーを意識しません。そのため、ノードにスケジュールされた後に実行に失敗する可能性があります。
9 - ネットワークポリシーを宣言する
このドキュメントでは、Pod同士の通信を制御するネットワークポリシーを定義するための、KubernetesのNetworkPolicy APIを使い始める手助けをします。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.8.バージョンを確認するには次のコマンドを実行してください: kubectl version.
ネットワークポリシーをサポートしているネットワークプロバイダーが設定済みであることを確認してください。さまざまなネットワークプロバイダーがNetworkPolicyをサポートしています。次に挙げるのは一例です。
備考:
上記のリストは製品名のアルファベット順にソートされていて、推奨順や好ましい順にソートされているわけではありません。このページの例は、Kubernetesクラスターでこれらのどのプロバイダーを使用していても有効です。nginx Deploymentを作成してService経由で公開する
Kubernetesのネットワークポリシーの仕組みを理解するために、まずはnginx Deploymentを作成することから始めましょう。
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
nginxという名前のService経由でDeploymentを公開します。
kubectl expose deployment nginx --port=80
service/nginx exposed
上記のコマンドを実行すると、nginx Podを持つDeploymentが作成され、そのDeploymentがnginxという名前のService経由で公開されます。nginxのPodおよびDeploymentはdefault名前空間の中にあります。
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
もう1つのPodからアクセスしてServiceを検証する
これで、新しいnginxサービスに他のPodからアクセスできるようになったはずです。default名前空間内の他のPodからnginx Serviceにアクセスするために、busyboxコンテナを起動します。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx Serviceへのアクセスを制限する
nginx Serviceへのアクセスを制限するために、access: trueというラベルが付いたPodだけがクエリできるようにします。次の内容でNetworkPolicyオブジェクトを作成してください。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
NetworkPolicyオブジェクトの名前は、有効なDNSサブドメイン名でなければなりません。
備考:
このNetworkPolicyには、ポリシーを適用するPodのグループを選択するためのpodSelectorが含まれています。このポリシーは、ラベルapp=nginxの付いたPodを選択していることがわかります。このラベルは、nginx Deployment内のPodに自動的に追加されたものです。空のpodSelectorは、その名前空間内のすべてのPodを選択します。Serviceにポリシーを割り当てる
kubectlを使って、上記のnginx-policy.yamlファイルからNetworkPolicyを作成します。
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
accessラベルが定義されていない状態でServiceへのアクセスをテストする
nginx Serviceに正しいラベルが付いていないPodからアクセスを試してみると、リクエストがタイムアウトします。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
accessラベルを定義して再テストする
正しいラベルが付いたPodを作成すると、リクエストが許可されるようになるのがわかります。
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
10 - クラウドコントローラーマネージャーの開発
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのcontrol planeコンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIをリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと下のクラウドインフラストラクチャー間の相互運用ロジックを分離することで、cloud-controller-managerコンポーネントはクラウドプロバイダを主なKubernetesプロジェクトと比較し異なるペースで機能をリリース可能にします。
背景
クラウドプロバイダーはKubernetesプロジェクトとは異なる速度で開発しリリースすることから、プロバイダー特有なコードをcloud-controller-managerバイナリから抽象化することで、クラウドベンダーはコアKubernetesコードから独立して発展することができます。
Kubernetesプロジェクトは、(クラウドプロバイダーの)独自実装を組み込めるGoインターフェースを備えたcloud-controller-managerのスケルトンコードを提供しています。これは、クラウドプロバイダーがKubernetesコアからパッケージをインポートすることでcloud-controller-managerを実装できることを意味します。各クラウドプロバイダーは利用可能なクラウドプロバイダーのグローバル変数を更新するためにcloudprovider.RegisterCloudProviderを呼び出し、独自のコードを登録します。
開発
Kubernetesには登録されていない独自クラウドプロバイダー
Kubernetesには登録されていない独自のクラウドプロバイダーのクラウドコントローラーマネージャーを構築するには、
- cloudprovider.Interfaceを満たす go パッケージを実装します。
- Kubernetesのコアにあるcloud-controller-managerの
main.goをあなたのmain.goのテンプレートとして利用します。上で述べたように、唯一の違いはインポートされるクラウドパッケージのみです。 - クラウドパッケージを
main.goにインポートし、パッケージにcloudprovider.RegisterCloudProviderを実行するためのinitブロックがあることを確認します。
多くのクラウドプロバイダーはオープンソースとしてコントローラーマネージャーのコードを公開しています。新たにcloud-controller-managerをスクラッチから開発する際には、既存のKubernetesには登録されていない独自クラウドプロバイダーのコントローラーマネージャーを開始地点とすることができます。
Kubernetesに登録されているクラウドプロバイダー
Kubernetesに登録されているクラウドプロバイダーであれば、DaemonSetを使ってあなたのクラスターで動かすことができます。詳細についてはKubernetesクラウドコントローラーマネージャーを参照してください。
11 - Kubernetes向けetcdクラスターの運用
etcdは 一貫性、高可用性を持ったキーバリューストアで、Kubernetesの全てのクラスター情報の保存場所として利用されています。
etcdをKubernetesのデータストアとして使用する場合、必ずデータのバックアッププランを作成して下さい。
公式ドキュメントでetcdに関する詳細な情報を見つけることができます。
始める前に
Kubernetesクラスターが必要で、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。 コントロールプレーンノード以外に少なくとも2つのノードを持つクラスターで、このガイドに従うことを推奨します。 まだクラスターを用意していない場合は、minikubeを使用して作成することができます。
前提条件
-
etcdは、奇数のメンバーを持つクラスターとして実行します。
-
etcdはリーダーベースの分散システムです。リーダーが定期的に全てのフォロワーにハートビートを送信し、クラスターの安定性を維持するようにします。
-
リソース不足が発生しないようにします。
クラスターのパフォーマンスと安定性は、ネットワークとディスクのI/Oに敏感です。 リソース不足はハートビートのタイムアウトを引き起こし、クラスターの不安定化につながる可能性があります。 不安定なetcdは、リーダーが選出されていないことを意味します。 そのような状況では、クラスターは現在の状態に変更を加えることができません。 これは、新しいPodがスケジュールされないことを意味します。
-
Kubernetesクラスターの安定性には、etcdクラスターの安定性が不可欠です。 したがって、etcdクラスターは専用のマシンまたは保証されたリソース要件を持つ隔離された環境で実行してください。
-
本番環境で実行するために推奨される最低限のetcdバージョンは、
3.4.22以降あるいは3.5.6以降です。
リソース要件
限られたリソースでetcdを運用するのはテスト目的にのみ適しています。 本番環境へのデプロイには、高度なハードウェア構成が必要です。 本番環境へetcdをデプロイする前に、リソース要件を確認してください。
ツール
どの作業に取り組んでいるかにより、etcdctlツールまたはetcdutlツールが必要になります(両方必要になる場合もあります)。
etcdctlとetcdutlの理解
etcdctlとetcdutlはetcdクラスターと対話するために使用されるコマンドラインツールですが、それぞれ異なる目的を持っています。
-
etcdctl: これはネットワーク経由でetcdと対話するための主要なコマンドラインクライアントです。 キーと値の管理、クラスターの管理、ヘルスチェックなど、日常的な操作に使用されます。 -
etcdutl: これはetcdデータファイルに直接操作を行うための管理ユーティリティで、etcdバージョン間のデータ移行、データベースのデフラグ、スナップショットの復元、データ整合性の検証などを含みます。 ネットワーク経由の操作の場合は、etcdctlを使用すべきです。
etcdutlに関する詳細情報については、etcdリカバリのドキュメントを参照してください。
etcdクラスターの起動
このセクションでは、単一ノードおよびマルチノードetcdクラスターの起動について説明します。
単一ノードetcdクラスター
単一ノードetcdクラスターは、テスト目的でのみ使用してください。
-
以下を実行します:
etcd --listen-client-urls=http://$PRIVATE_IP:2379 \ --advertise-client-urls=http://$PRIVATE_IP:2379 -
Kubernetes APIサーバーをフラグ
--etcd-servers=$PRIVATE_IP:2379で起動します。PRIVATE_IPがetcdクライアントIPに設定されていることを確認してください。
マルチノードetcdクラスター
耐久性と高可用性のために、本番環境ではマルチノードクラスターとしてetcdを実行し、定期的にバックアップを取ります。 本番環境では5つのメンバーによるクラスターが推奨されます。 詳細はFAQドキュメントを参照してください。
etcdクラスターは、静的なメンバー情報、または動的な検出によって構成されます。 クラスタリングに関する詳細は、etcdクラスタリングドキュメントを参照してください。
例として、次のクライアントURLで実行される5つのメンバーによるetcdクラスターを考えてみます。
5つのURLは、http://$IP1:2379、http://$IP2:2379、http://$IP3:2379、http://$IP4:2379、およびhttp://$IP5:2379です。Kubernetes APIサーバーを起動するには、
-
以下を実行します:
etcd --listen-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 --advertise-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 -
フラグ
--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379を使ってKubernetes APIサーバーを起動します。IP<n>変数がクライアントのIPアドレスに設定されていることを確認してください。
ロードバランサーを使用したマルチノードetcdクラスター
ロードバランシングされたetcdクラスターを実行するには、次の手順に従います。
- etcdクラスターを設定します。
- etcdクラスターの前にロードバランサーを設定します。
例えば、ロードバランサーのアドレスを
$LBとします。 - フラグ
--etcd-servers=$LB:2379を使ってKubernetes APIサーバーを起動します。
etcdクラスターのセキュリティ確保
etcdへのアクセスはクラスター内でのルート権限に相当するため、理想的にはAPIサーバーのみがアクセスできるようにするべきです。 データの機密性を考慮して、etcdクラスターへのアクセス権を必要とするノードのみに付与することが推奨されます。
etcdをセキュアにするためには、ファイアウォールのルールを設定するか、etcdによって提供されるセキュリティ機能を使用します。
etcdのセキュリティ機能はx509公開鍵基盤(PKI)に依存します。
この機能を使用するには、キーと証明書のペアを生成して、セキュアな通信チャンネルを確立します。
例えば、etcdメンバー間の通信をセキュアにするためにpeer.keyとpeer.certのキーペアを使用し、etcdとそのクライアント間の通信をセキュアにするためにclient.keyとclient.certを使用します。
クライアント認証用のキーペアとCAファイルを生成するには、etcdプロジェクトによって提供されているサンプルスクリプトを参照してください。
通信のセキュリティ確保
セキュアなピア通信を持つetcdを構成するためには、--peer-key-file=peer.keyおよび--peer-cert-file=peer.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
同様に、セキュアなクライアント通信を持つetcdを構成するためには、--key-file=k8sclient.keyおよび--cert-file=k8sclient.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
セキュアな通信を使用するクライアントコマンドの例は以下の通りです:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
etcdクラスターへのアクセス制限
セキュアな通信を構成した後、TLS認証を使用して、etcdクラスターへのアクセスをKubernetes APIサーバーのみに制限します。
例えば、CA etcd.caによって信頼されるキーペアk8sclient.keyとk8sclient.certを考えてみます。
--client-cert-authとTLSを使用してetcdが構成されている場合、etcdは--trusted-ca-fileフラグで渡されたCAまたはシステムのCAを使用してクライアントからの証明書を検証します。
--client-cert-auth=trueおよび--trusted-ca-file=etcd.caフラグを指定することで、証明書k8sclient.certを持つクライアントのみにアクセスを制限します。
etcdが正しく構成されると、有効な証明書を持つクライアントのみがアクセスできます。
Kubernetes APIサーバーにアクセス権を与えるためには、--etcd-certfile=k8sclient.cert、--etcd-keyfile=k8sclient.keyおよび--etcd-cafile=ca.certフラグで構成します。
備考:
etcd認証は、Kubernetesでは現在サポートされていません。障害が発生したetcdメンバーの交換
etcdクラスターは、一部のメンバーの障害を許容することで高可用性を実現します。 しかし、クラスターの全体的な状態を改善するためには、障害が発生したメンバーを直ちに交換することが重要です。 複数のメンバーに障害が発生した場合は、1つずつ交換します。 障害が発生したメンバーを交換するには、メンバーを削除し、新しいメンバーを追加するという2つのステップがあります。
etcdは内部でユニークなメンバーIDを保持していますが、人的なミスを避けるためにも各メンバーにはユニークな名前を使用することが推奨されます。
例えば、3つのメンバーのetcdクラスターを考えてみましょう。
URLがmember1=http://10.0.0.1、member2=http://10.0.0.2、そしてmember3=http://10.0.0.3だとします。
member1に障害が発生した場合、member4=http://10.0.0.4で交換します。
-
障害が発生した
member1のメンバーIDを取得します:etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list次のメッセージが表示されます:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379 91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379 fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379 -
以下のいずれかを行います:
- 各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、
--etcd-serversフラグから障害が発生したメンバーを削除し、各Kubernetes APIサーバーを再起動します。 - 各Kubernetes APIサーバーが単一のetcdメンバーと通信している場合、障害が発生したetcdと通信しているKubernetes APIサーバーを停止します。
- 各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、
-
壊れたノード上のetcdサーバーを停止します。 Kubernetes APIサーバー以外のクライアントからetcdにトラフィックが流れている可能性があり、データディレクトリへの書き込みを防ぐためにすべてのトラフィックを停止することが望ましいです。
-
メンバーを削除します:
etcdctl member remove 8211f1d0f64f3269次のメッセージが表示されます:
Removed member 8211f1d0f64f3269 from cluster -
新しいメンバーを追加します:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380次のメッセージが表示されます:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4 -
IP
10.0.0.4のマシン上で新たに追加されたメンバーを起動します:export ETCD_NAME="member4" export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380" export ETCD_INITIAL_CLUSTER_STATE=existing etcd [flags] -
以下のいずれかを行います:
- 各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、
--etcd-serversフラグに新たに追加されたメンバーを加え、各Kubernetes APIサーバーを再起動します。 - 各Kubernetes APIサーバーが単一のetcdメンバーと通信している場合、ステップ2で停止したKubernetes APIサーバーを起動します。 その後、Kubernetes APIサーバークライアントを再度構成して、停止されたKubernetes APIサーバーへのリクエストをルーティングします。 これは多くの場合、ロードバランサーを構成することで行われます。
- 各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、
クラスターの再構成に関する詳細については、etcd再構成ドキュメントを参照してください。
etcdクラスターのバックアップ
すべてのKubernetesオブジェクトはetcdに保存されています。 定期的にetcdクラスターのデータをバックアップすることは、すべてのコントロールプレーンノードを失うなどの災害シナリオでKubernetesクラスターを復旧するために重要です。 スナップショットファイルには、すべてのKubernetesの状態と重要な情報が含まれています。 機密性の高いKubernetesデータを安全に保つために、スナップショットファイルを暗号化してください。
etcdクラスターのバックアップは、etcdのビルトインスナップショットとボリュームスナップショットの2つの方法で実現できます。
ビルトインスナップショット
etcdはビルトインスナップショットをサポートしています。
スナップショットは、etcdctl snapshot saveコマンドを使用してライブメンバーから、あるいはetcdプロセスによって現在使用されていないデータディレクトリからmember/snap/dbファイルをコピーして作成できます。
スナップショットを作成しても、メンバーのパフォーマンスに影響はありません。
以下は、$ENDPOINTによって提供されるキースペースのスナップショットをsnapshot.dbファイルに作成する例です:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
スナップショットを確認します:
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
ボリュームスナップショット
etcdがAmazon Elastic Block Storeのようなバックアップをサポートするストレージボリューム上で実行されている場合、ストレージボリュームのスナップショットを作成することによってetcdデータをバックアップします。
etcdctlオプションを使用したスナップショット
etcdctlによって提供されるさまざまなオプションを使用してスナップショットを作成することもできます。例えば
ETCDCTL_API=3 etcdctl -h
はetcdctlから利用可能なさまざまなオプションを一覧表示します。 例えば、以下のようにエンドポイント、証明書、キーを指定してスナップショットを作成することができます:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
ここで、trusted-ca-file、cert-file、key-fileはetcd Podの説明から取得できます。
etcdクラスターのスケールアウト
etcdクラスターのスケールアウトは、パフォーマンスとのトレードオフで可用性を高めます。 スケーリングはクラスターのパフォーマンスや能力を高めるものではありません。 一般的なルールとして、etcdクラスターをスケールアウトまたはスケールインすることはありません。 etcdクラスターに自動スケーリンググループを設定しないでください。 公式にサポートされるどんなスケールの本番環境のKubernetesクラスターにおいても、常に静的な5つのメンバーのetcdクラスターを運用することを強く推奨します。
合理的なスケーリングは、より高い信頼性が求められる場合に、3つのメンバーで構成されるクラスターを5つのメンバーにアップグレードすることです。 既存のクラスターにメンバーを追加する方法については、etcdの再構成ドキュメントを参照してください。
etcdクラスターの復元
etcdは、major.minorバージョンのetcdプロセスから取得されたスナップショットからの復元をサポートしています。 異なるパッチバージョンのetcdからのバージョン復元もサポートされています。 復元操作は、障害が発生したクラスターのデータを回復するために用いられます。
復元操作を開始する前に、スナップショットファイルが存在している必要があります。 これは、以前のバックアップ操作からのスナップショットファイルでも、残っているデータディレクトリからのスナップショットファイルでも構いません。
クラスターを復元する場合は、--data-dirオプションを使用して、クラスターをどのフォルダーに復元するかを指定します:
ETCDCTL_API=3 etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
ここで、<data-dir-location>は復元プロセス中に作成されるディレクトリです。
もう一つの例としては、まずETCDCTL_API環境変数をエクスポートします:
export ETCDCTL_API=3
etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
<data-dir-location>が以前と同じフォルダーである場合は、クラスターを復元する前にそれを削除してetcdプロセスを停止します。そうでない場合は、etcdの構成を変更し、復元後にetcdプロセスを再起動して新しいデータディレクトリを使用するようにします。
スナップショットファイルからクラスターを復元する方法と例についての詳細は、etcd災害復旧ドキュメントを参照してください。
復元されたクラスターのアクセスURLが前のクラスターと異なる場合、Kubernetes APIサーバーをそれに応じて再設定する必要があります。
この場合、--etcd-servers=$OLD_ETCD_CLUSTERのフラグの代わりに、--etcd-servers=$NEW_ETCD_CLUSTERのフラグでKubernetes APIサーバーを再起動します。
$NEW_ETCD_CLUSTERと$OLD_ETCD_CLUSTERをそれぞれのIPアドレスに置き換えてください。
etcdクラスターの前にロードバランサーを使用している場合、代わりにロードバランサーを更新する必要があるかもしれません。
etcdメンバーの過半数に永続的な障害が発生した場合、etcdクラスターは故障したと見なされます。 このシナリオでは、Kubernetesは現在の状態に対して変更を加えることができません。 スケジュールされたPodは引き続き実行されるかもしれませんが、新しいPodはスケジュールできません。 このような場合、etcdクラスターを復旧し、必要に応じてKubernetes APIサーバーを再設定して問題を修正します。
備考:
クラスター内でAPIサーバーが実行されている場合、etcdのインスタンスを復元しようとしないでください。 代わりに、以下の手順に従ってetcdを復元してください:
- すべてのAPIサーバーインスタンスを停止
- すべてのetcdインスタンスで状態を復元
- すべてのAPIサーバーインスタンスを再起動
また、kube-scheduler、kube-controller-manager、kubeletなどのコンポーネントを再起動することもお勧めします。
これは、これらが古いデータに依存していないことを確認するためです。実際には、復元には少し時間がかかります。
復元中、重要なコンポーネントはリーダーロックを失い、自動的に再起動します。
etcdクラスターのアップグレード
etcdのアップグレードに関する詳細は、etcdアップグレードのドキュメントを参照してください。
備考:
アップグレードを開始する前に、まずetcdクラスターをバックアップしてください。etcdクラスターのメンテナンス
etcdのメンテナンスに関する詳細は、etcdメンテナンスのドキュメントを参照してください。
備考:
デフラグメンテーションはコストがかかる操作のため、できるだけ頻繁に実行しないようにしてください。 一方で、etcdメンバーがストレージのクォータを超えないようにする必要もあります。 Kubernetesプロジェクトでは、デフラグメンテーションを行う際には、etcd-defragなどのツールを使用することを推奨しています。
また、デフラグメンテーションを定期的に実行するために、KubernetesのCronJobとしてデフラグメンテーションツールを実行することもできます。
詳細はetcd-defrag-cronjob.yamlを参照してください。
12 - ノードを安全にドレインする
このページでは、ノードを安全にドレインする方法を示します。 オプションで、定義されたPodDisruptionBudgetを考慮することも可能です。
始める前に
このタスクを実行するには、以下のいずれかの前提条件を満たしている必要があります:
- ノードのドレイン中にアプリケーションの高可用性を必要としない
- PodDisruptionBudgetの概念に関する記事を読み、必要とするアプリケーションに対してPodDisruptionBudgetを設定していること
(オプション)Disruption Budgetを設定する
メンテナンス中もワークロードの可用性を維持するために、PodDisruptionBudgetを設定できます。
ドレイン対象のノード上で動作している、または今後動作する可能性のあるアプリケーションにとって可用性が重要である場合は、まずPodDisruptionBudgetを設定してから、このガイドに従ってください。
ノードのドレイン中に不具合のあるアプリケーションの削除を許容するため、PodDisruptionBudgetにはAlwaysAllowのUnhealthyPodEvictionPolicyを設定することが推奨されます。
デフォルトの挙動では、アプリケーションのPodが健全になるまで、ドレインは実行されません。
kubectl drainを使ってノードをサービスから除外する
ノードに対してメンテナンス(例: カーネルのアップグレードやハードウェアのメンテナンスなど)を行う前に、kubectl drainを使用して、そのノード上のすべてのPodを安全に退避させることができます。
安全に退避すると、Podのコンテナが正常に終了し、指定したPodDisruptionBudgetも尊重されます。
kubectl drainが正常に終了した場合、それは(前段で述べた除外対象を除く)すべてのPodが安全に削除されたことを示します(望ましい正常終了期間および定義されたPodDisruptionBudgetは尊重されます)。
その時点で、ノードを停止しても安全です。
物理マシンの場合は電源を落とすことができ、クラウドプラットフォーム上であれば仮想マシンを削除しても差し支えありません。
備考:
node.kubernetes.io/unschedulable taintを許容する新しいPodが存在する場合、それらのPodはドレイン済みのノードにスケジューリングされる可能性があります。
DaemonSet以外では、そのtaintを許容しないようにしてください。
あなた、または他のAPIユーザーがPodのnodeNameフィールドを(スケジューラーを介さずに)直接設定した場合、そのPodは指定されたノードにバインドされ、そのノードがドレイン済みでスケジューリング不可とマークされていたとしても、そのノード上で実行されます。
まず、ドレインしたいノードの名前を特定します。 クラスター内のすべてのノードは、次のコマンドで一覧表示できます:
kubectl get nodes
次に、ノードをドレインするようにKubernetesに指示します:
kubectl drain --ignore-daemonsets <node name>
DaemonSetによって管理されているPodが存在する場合は、ノードを正常にドレインするために、kubectlに--ignore-daemonsetsを指定する必要があります。
kubectl drainサブコマンド単体では、実際にはDaemonSetのPodをノードからドレインしません:
DaemonSetコントローラー(コントロールプレーンの一部)は、欠落したPodをただちに同等の新しいPodで置き換えます。
また、DaemonSetコントローラーはスケジューリング不可のtaintを無視するPodも作成するため、ドレイン中のノード上に新しいPodが起動されることがあります。
エラーなくコマンドが完了したら、そのノードの電源を切ることができます(あるいは同等に、クラウドプラットフォーム上であれば、そのノードに対応する仮想マシンを削除することもできます)。 メンテナンス作業中にそのノードをクラスターに残しておいた場合は、作業完了後にKubernetesがそのノードへのPodのスケジューリングを再び可能にするために、次のコマンドを実行してください。
kubectl uncordon <node name>
複数ノードの並列ドレイン
kubectl drainコマンドは、一度に1つのノードに対してのみ発行すべきです。
ただし、異なるノードに対して、複数のkubectl drainコマンドを異なるターミナルまたはバックグラウンドで並行で実行することは可能です。
複数のドレインコマンドが同時に実行されていても、指定したPodDisruptionBudgetは引き続き順守されます。
たとえば、3つのレプリカを持つStatefulSetがあり、そのセットに対してminAvailable: 2を指定したPodDisruptionBudgetを設定している場合、kubectl drainは、3つのレプリカのPodがすべて健全である場合にのみ、そのStatefulSetのPodを退避させます。
このとき、複数のドレインコマンドを並行して発行した場合でも、KubernetesはPodDisruptionBudgetを順守し、任意の時点で使用不能なPodが1つ(replicas - minAvailableで計算)にとどまるように制御します。
健全なレプリカの数が指定したバジェットを下回る原因となるようなドレイン操作はブロックされます。
Eviction API
kubectl drainを使用したくないとき(外部コマンドの呼び出しを避けたい場合や、Podの退避プロセスをより細かく制御したい場合など)は、Eviction APIを用いてプログラムから退避を実行することもできます。
詳細は、APIを基点とした退避を参照してください。
次の項目
- PodDisruptionBudgetを設定してアプリケーションを保護する手順をご確認ください。
13 - クラスターのセキュリティ
このドキュメントでは、偶発的または悪意のあるアクセスからクラスターを保護するためのトピックについて説明します。 また、全体的なセキュリティに関する推奨事項を提供します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:
kubectl version.
Kubernetes APIへのアクセスの制御
Kubernetesは完全にAPI駆動であるため、誰がクラスターにアクセスできるか、どのようなアクションを実行できるかを制御・制限することが第一の防御策となります。
すべてのAPIトラフィックにTLS(Transport Layer Security)を使用する
Kubernetesは、クラスター内のすべてのAPI通信がデフォルトでTLSにより暗号化されていることを期待しており、大半のインストール方法では、必要な証明書を作成してクラスターコンポーネントに配布することができます。
コンポーネントやインストール方法によっては、HTTP上のローカルポートを有効にする場合があることに注意してください。管理者は、潜在的に保護されていないトラフィックを特定するために、各コンポーネントの設定に精通している必要があります。
APIの認証
クラスターのインストール時に、共通のアクセスパターンに合わせて、APIサーバーが使用する認証メカニズムを選択します。 例えば、シングルユーザーの小規模なクラスターでは、シンプルな証明書や静的なBearerトークンを使用することができます。 大規模なクラスターでは、ユーザーをグループに細分化できる既存のOIDCまたはLDAPサーバーを統合することができます。
ノード、プロキシ、スケジューラー、ボリュームプラグインなど、インフラの一部であるものも含めて、すべてのAPIクライアントを認証する必要があります。 これらのクライアントは通常、service accountsであるか、またはx509クライアント証明書を使用しており、クラスター起動時に自動的に作成されるか、クラスターインストールの一部として設定されます。
詳細については、認証を参照してください。
APIの認可
認証されると、すべてのAPIコールは認可チェックを通過することになります。
Kubernetesには、統合されたRBACコンポーネントが搭載されており、入力されたユーザーやグループを、ロールにまとめられたパーミッションのセットにマッチさせます。 これらのパーミッションは、動詞(get, create, delete)とリソース(pods, services, nodes)を組み合わせたもので、ネームスペース・スコープまたはクラスター・スコープに対応しています。 すぐに使えるロールのセットが提供されており、クライアントが実行したいアクションに応じて、デフォルトで適切な責任の分離を提供します。
NodeとRBACの承認者は、NodeRestrictionのアドミッションプラグインと組み合わせて使用することをお勧めします。
認証の場合と同様に、小規模なクラスターにはシンプルで幅広い役割が適切かもしれません。 しかし、より多くのユーザーがクラスターに関わるようになるとチームを別の名前空間に分け、より限定的な役割を持たせることが必要になるかもしれません。 認可においては、あるオブジェクトの更新が、他の場所でどのようなアクションを起こすかを理解することが重要です。
たとえば、ユーザーは直接Podを作成することはできませんが、ユーザーに代わってPodを作成するDeploymentの作成を許可することで、間接的にそれらのPodを作成することができます。 同様に、APIからノードを削除すると、そのノードにスケジューリングされていたPodが終了し、他のノードに再作成されます。 すぐに使えるロールは、柔軟性と一般的なユースケースのバランスを表していますが、より限定的なロールは、偶発的なエスカレーションを防ぐために慎重に検討する必要があります。 すぐに使えるロールがニーズを満たさない場合は、ユースケースに合わせてロールを作成することができます。
詳しくはauthorization reference sectionに参照してください。
Kubeletへのアクセスの制御
Kubeletsは、ノードやコンテナの強力な制御を可能にするHTTPSエンドポイントを公開しています。 デフォルトでは、KubeletsはこのAPIへの認証されていないアクセスを許可しています。
本番環境のクラスターでは、Kubeletの認証と認可を有効にする必要があります。
詳細は、Kubelet 認証/認可に参照してください。
ワークロードやユーザーのキャパシティーを実行時に制御
Kubernetesにおける権限付与は、意図的にハイレベルであり、リソースに対する粗いアクションに焦点を当てています。
より強力なコントロールはpoliciesとして存在し、それらのオブジェクトがクラスターや自身、その他のリソースにどのように作用するかをユースケースによって制限します。
クラスターのリソース使用量の制限
リソースクォータは、ネームスペースに付与されるリソースの数や容量を制限するものです。
これは、ネームスペースが割り当てることのできるCPU、メモリー、永続的なディスクの量を制限するためによく使われますが、各ネームスペースに存在するPod、サービス、ボリュームの数を制御することもできます。
Limit rangesは、上記のリソースの一部の最大または最小サイズを制限することで、ユーザーがメモリーなどの一般的に予約されたリソースに対して不当に高いまたは低い値を要求するのを防いだり、何も指定されていない場合にデフォルトの制限を提供したりします。
コンテナが利用する特権の制御
Podの定義には、security contextが含まれており、ノード上の特定の Linux ユーザー(rootなど)として実行するためのアクセス、特権的に実行するためのアクセス、ホストネットワークにアクセスするためのアクセス、その他の制御を要求することができます。 Pod security policiesは、危険なセキュリティコンテキスト設定を提供できるユーザーやサービスアカウントを制限することができます。
たとえば、Podのセキュリティポリシーでは、ボリュームマウント、特にhostPathを制限することができ、これはPodの制御すべき側面です。
一般に、ほとんどのアプリケーションワークロードでは、ホストリソースへのアクセスを制限する必要があります。
ホスト情報にアクセスすることなく、ルートプロセス(uid 0)として正常に実行できます。
ただし、ルートユーザーに関連する権限を考慮して、非ルートユーザーとして実行するようにアプリケーションコンテナを記述する必要があります。
コンテナが不要なカーネルモジュールをロードしないようにします
Linuxカーネルは、ハードウェアが接続されたときやファイルシステムがマウントされたときなど、特定の状況下で必要となるカーネルモジュールをディスクから自動的にロードします。 特にKubernetesでは、非特権プロセスであっても、適切なタイプのソケットを作成するだけで、特定のネットワークプロトコル関連のカーネルモジュールをロードさせることができます。これにより、管理者が使用されていないと思い込んでいるカーネルモジュールのセキュリティホールを攻撃者が利用できる可能性があります。 特定のモジュールが自動的にロードされないようにするには、そのモジュールをノードからアンインストールしたり、ルールを追加してブロックしたりします。
ほとんどのLinuxディストリビューションでは、/etc/modprobe.d/kubernetes-blacklist.confのような内容のファイルを作成することで実現できます。
# DCCPは必要性が低く、複数の深刻な脆弱性があり、保守も十分ではありません。
blacklist dccp
# SCTPはほとんどのKubernetesクラスターでは使用されておらず、また過去には脆弱性がありました。
blacklist sctp
モジュールのロードをより一般的にブロックするには、SELinuxなどのLinuxセキュリティモジュールを使って、コンテナに対する module_request権限を完全に拒否し、いかなる状況下でもカーネルがコンテナ用のモジュールをロードできないようにすることができます。
(Podは、手動でロードされたモジュールや、より高い権限を持つプロセスに代わってカーネルがロードしたモジュールを使用することはできます)。
ネットワークアクセスの制限
名前空間のネットワークポリシーにより、アプリケーション作成者は、他の名前空間のPodが自分の名前空間内のPodやポートにアクセスすることを制限することができます。
サポートされているKubernetes networking providersの多くは、ネットワークポリシーを尊重するようになりました。 クォータやリミットの範囲は、ユーザーがノードポートや負荷分散サービスを要求するかどうかを制御するためにも使用でき、多くのクラスターでは、ユーザーのアプリケーションがクラスターの外で見えるかどうかを制御できます。 ノードごとのファイアウォール、クロストークを防ぐための物理的なクラスターノードの分離、高度なネットワークポリシーなど、プラグインや環境ごとにネットワークルールを制御する追加の保護機能が利用できる場合もあります。
クラウドメタデータのAPIアクセスを制限
クラウドプラットフォーム(AWS、Azure、GCEなど)では、しばしばメタデータサービスをインスタンスローカルに公開しています。 デフォルトでは、これらのAPIはインスタンス上で実行されているPodからアクセスでき、そのノードのクラウド認証情報や、kubelet認証情報などのプロビジョニングデータを含むことができます。 これらの認証情報は、クラスター内でのエスカレーションや、同じアカウントの他のクラウドサービスへのエスカレーションに使用できます。
クラウドプラットフォーム上でKubernetesを実行する場合は、インスタンスの認証情報に与えられるパーミッションを制限し、ネットワークポリシーを使用してメタデータAPIへのPodのアクセスを制限し、プロビジョニングデータを使用してシークレットを配信することは避けてください。
Podのアクセス可能ノードを制御
デフォルトでは、どのノードがPodを実行できるかについての制限はありません。 Kubernetesは、エンドユーザーが利用できるNode上へのPodのスケジューリングとTaintとTolerationを提供します。 多くのクラスターでは、ワークロードを分離するためにこれらのポリシーを使用することは、作者が採用したり、ツールを使って強制したりする慣習になっています。
管理者としては、ベータ版のアドミッションプラグイン「PodNodeSelector」を使用して、ネームスペース内のPodをデフォルトまたは特定のノードセレクタを必要とするように強制することができます。 エンドユーザーがネームスペースを変更できない場合は、特定のワークロード内のすべてのPodの配置を強く制限することができます。
クラスターのコンポーネントの保護
このセクションでは、クラスターを危険から守るための一般的なパターンを説明します。
etcdへのアクセスの制限
API用のetcdバックエンドへの書き込みアクセスは、クラスター全体のrootを取得するのと同等であり、読み取りアクセスはかなり迅速にエスカレートするために使用できます。 管理者は、TLSクライアント証明書による相互認証など、APIサーバーからetcdサーバーへの強力な認証情報を常に使用すべきであり、API サーバーのみがアクセスできるファイアウォールの後ろにetcdサーバーを隔離することがしばしば推奨されます。
注意:
クラスター内の他のコンポーネントが、完全なキースペースへの読み取りまたは書き込みアクセスを持つマスターetcdインスタンスへのアクセスを許可することは、クラスター管理者のアクセスを許可することと同じです。 マスター以外のコンポーネントに別のetcdインスタンスを使用するか、またはetcd ACLを使用してキースペースのサブセットへの読み取りおよび書き込みアクセスを制限することを強く推奨します。監査ログの有効
audit loggerはベータ版の機能で、APIによって行われたアクションを記録し、侵害があった場合に後から分析できるようにするものです。
監査ログを有効にして、ログファイルを安全なサーバーにアーカイブすることをお勧めします。
アルファまたはベータ機能へのアクセスの制限
アルファ版およびベータ版のKubernetesの機能は活発に開発が行われており、セキュリティ上の脆弱性をもたらす制限やバグがある可能性があります。 常に、アルファ版またはベータ版の機能が提供する価値と、セキュリティ体制に起こりうるリスクを比較して評価してください。 疑問がある場合は、使用しない機能を無効にしてください。
インフラの認証情報を頻繁に交換
秘密やクレデンシャルの有効期間が短いほど、攻撃者がそのクレデンシャルを利用することは難しくなります。 証明書の有効期間を短く設定し、そのローテーションを自動化します。 発行されたトークンの利用可能期間を制御できる認証プロバイダーを使用し、可能な限り短いライフタイムを使用します。 外部統合でサービス・アカウント・トークンを使用する場合、これらのトークンを頻繁にローテーションすることを計画します。 例えば、ブートストラップ・フェーズが完了したら、ノードのセットアップに使用したブートストラップ・トークンを失効させるか、その認証を解除する必要があります。
サードパーティの統合を有効にする前に確認
Kubernetesへの多くのサードパーティの統合は、クラスターのセキュリティプロファイルを変更する可能性があります。 統合を有効にする際には、アクセスを許可する前に、拡張機能が要求するパーミッションを常に確認してください。
例えば、多くのセキュリティ統合は、事実上そのコンポーネントをクラスター管理者にしているクラスター上のすべての秘密を見るためのアクセスを要求するかもしれません。
疑問がある場合は、可能な限り単一の名前空間で機能するように統合を制限してください。
Podを作成するコンポーネントも、kube-system名前空間のような名前空間内で行うことができれば、予想外に強力になる可能性があります。これは、サービスアカウントのシークレットにアクセスしたり、サービスアカウントに寛容なpod security policiesへのアクセスが許可されている場合に、昇格したパーミッションでPodが実行される可能性があるからです。
etcdにあるSecretを暗号化
一般的に、etcdデータベースにはKubernetes APIを介してアクセス可能なあらゆる情報が含まれており、クラスターの状態に対する大きな可視性を攻撃者へ与える可能性があります。 よく吟味されたバックアップおよび暗号化ソリューションを使用して、常にバックアップを暗号化し、可能な場合はフルディスク暗号化の使用を検討してください。
Kubernetesは1.7で導入された機能であるencryption at restをサポートしており、これは1.13からはベータ版となっています。
これは、etcdのSecretリソースを暗号化し、etcdのバックアップにアクセスした人が、それらのシークレットの内容を見ることを防ぎます。
この機能は現在ベータ版ですが、バックアップが暗号化されていない場合や、攻撃者がetcdへの読み取りアクセスを得た場合に、追加の防御レベルを提供します。
セキュリティアップデートのアラートの受信と脆弱性の報告
kubernetes-announceに参加してください。 グループに参加すると、セキュリティアナウンスに関するメールを受け取ることができます。 脆弱性の報告方法については、security reportingページを参照してください。
14 - クラスターのアップグレード
このページでは、Kubernetesクラスターをアップグレードする際に従うべき手順の概要を提供します。
クラスターのアップグレード方法は、初期のデプロイ方法やその後の変更によって異なります。
大まかな手順は以下の通りです:
- コントロールプレーンのアップグレード
- クラスター内にあるノードのアップグレード
- kubectlなど、クライアントのアップグレード
- 新しいKubernetesバージョンに伴うAPI変更に基づいたマニフェストやその他のリソースの調整
始める前に
既存のクラスターが必要です。このページではKubernetes 1.33からKubernetes 1.34へのアップグレードについて説明しています。現在のクラスターがKubernetes 1.33を実行していない場合は、アップグレードしようとしているKubernetesバージョンのドキュメントを確認してください。
アップグレード方法
kubeadm
クラスターがkubeadmツールを使用してデプロイされた場合の詳細なアップグレード方法は、kubeadmクラスターのアップグレードを参照してください。
クラスターをアップグレードしたら、忘れずに最新バージョンのkubectlをインストールしてください。
手動デプロイ
注意:
これらの手順は、ネットワークおよびストレージプラグインなどのサードパーティ製拡張機能には対応していません。次の順序でコントロールプレーンを手動で更新する必要があります:
- etcd(すべてのインスタンス)
- kube-apiserver(すべてのコントロールプレーンホスト)
- kube-controller-manager
- kube-scheduler
- クラウドコントローラーマネージャー(使用している場合)
この時点で、最新バージョンのkubectlをインストールしてください。
クラスター内の各ノードに対して、そのノードをドレインし、1.34 kubeletを使用する新しいノードと置き換えるか、そのノードのkubeletをアップグレードして再稼働させます。
注意:
kubeletをアップグレードする前にノードをドレインすることで、Podが再収容され、コンテナが再作成されるため、一部のセキュリティ問題や重要なバグの解決が必要な場合があります。その他のデプロイ
クラスターデプロイメントツールのドキュメントを参照して、メンテナンスの推奨手順を確認してください。
アップグレード後のタスク
クラスターのストレージAPIバージョンを切り替える
クラスターの内部表現でアクティブなKubernetesリソースのためにetcdにシリアル化されるオブジェクトは、特定のAPIバージョンを使用して書き込まれます。
サポートされるAPIが変更されると、これらのオブジェクトは新しいAPIで再書き込みする必要があります。これを行わないと、最終的にはKubernetes APIサーバーによってデコードまたは使用できなくなるリソースが発生する可能性があります。
影響を受ける各オブジェクトについて、最新のサポートされるAPIを使用して取得し、最新のサポートされるAPIを使用して再書き込みします。
マニフェストの更新
新しいKubernetesバージョンへのアップグレードにより、新しいAPIが提供されることがあります。
異なるAPIバージョン間でマニフェストを変換するためにkubectl convertコマンドを使用できます。例えば:
kubectl convert -f pod.yaml --output-version v1
kubectlツールはpod.yamlの内容を、kindがPod(変更なし)で、apiVersionが改訂されたマニフェストに置き換えます。
デバイスプラグイン
クラスターがデバイスプラグインを実行しており、ノードを新しいデバイスプラグインAPIバージョンを含むKubernetesリリースにアップグレードする必要がある場合、デバイスプラグインをアップグレードして両方のバージョンをサポートする必要があります。これにより、アップグレード中にデバイスの割り当てが正常に完了し続けることが保証されます。
詳細については、API互換性およびkubeletのデバイスマネージャーAPIバージョンを参照してください。
15 - クラスターでカスケード削除を使用する
このページでは、ガベージコレクション中にクラスターで使用するカスケード削除のタイプを指定する方法を示します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
また、さまざまな種類のカスケード削除を試すために、サンプルのDeploymentを作成する必要があります。 タイプごとにDeploymentを再作成する必要があります。
Podのオーナーリファレンスを確認する
PodにownerReferencesフィールドが存在することを確認します:
kubectl get pods -l app=nginx --output=yaml
出力には、次のようにownerReferencesフィールドがあります。
apiVersion: v1
...
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-6b474476c4
uid: 4fdcd81c-bd5d-41f7-97af-3a3b759af9a7
...
フォアグラウンドカスケード削除を使用する
デフォルトでは、Kubernetesはバックグラウンドカスケード削除を使用して、オブジェクトの依存関係を削除します。
クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIのいずれかを使用して、フォアグラウンドカスケード削除に切り替えることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlまたはKubernetes APIを使用して、フォアグラウンドカスケード削除を使用してオブジェクトを削除することができます。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=foreground
Kubernetes APIを使用する
-
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080 -
削除のトリガーとして
curlを使用します:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \ -H "Content-Type: application/json"出力には、次のように
foregroundDeletionファイナライザーが含まれています。"kind": "Deployment", "apiVersion": "apps/v1", "metadata": { "name": "nginx-deployment", "namespace": "default", "uid": "d1ce1b02-cae8-4288-8a53-30e84d8fa505", "resourceVersion": "1363097", "creationTimestamp": "2021-07-08T20:24:37Z", "deletionTimestamp": "2021-07-08T20:27:39Z", "finalizers": [ "foregroundDeletion" ] ...
バッググラウンドカスケード削除を使用する
- サンプルのDeploymentを作成する。
- クラスターが動作しているKubernetesのバージョンに応じて、
kubectlまたはKubernetes APIのいずれかを使用してDeploymentを削除します。バージョンを確認するには次のコマンドを実行してください:
kubectl version.
kubectlまたはKubernetes APIを使用して、バックグラウンドカスケード削除を使用してオブジェクトを削除できます。
Kubernetesはデフォルトでバックグラウンドカスケード削除を使用し、--cascadeフラグまたはpropagationPolicy引数なしで以下のコマンドを実行した場合も同様です。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=background
Kubernetes APIを使用する
-
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080 -
削除のトリガーとして
curlを使用します:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \ -H "Content-Type: application/json"出力は、次のようになります。
"kind": "Status", "apiVersion": "v1", ... "status": "Success", "details": { "name": "nginx-deployment", "group": "apps", "kind": "deployments", "uid": "cc9eefb9-2d49-4445-b1c1-d261c9396456" }
オーナーオブジェクトの削除と従属オブジェクトの孤立
デフォルトでは、Kubernetesにオブジェクトの削除を指示すると、コントローラーは従属オブジェクトも削除します。クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIを使用して、これらの従属オブジェクトをKubernetesでorphanにすることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=orphan
Kubernetes APIを使用する
-
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080 -
削除のトリガーとして
curlを使用します:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \ -H "Content-Type: application/json"出力には、次のように
finalizersフィールドにorphanが含まれます。"kind": "Deployment", "apiVersion": "apps/v1", "namespace": "default", "uid": "6f577034-42a0-479d-be21-78018c466f1f", "creationTimestamp": "2021-07-09T16:46:37Z", "deletionTimestamp": "2021-07-09T16:47:08Z", "deletionGracePeriodSeconds": 0, "finalizers": [ "orphan" ], ...
Deploymentによって管理されているPodがまだ実行中であることを確認できます。
kubectl get pods -l app=nginx
次の項目
- Kubernetesのオーナーと従属について学ぶ。
- Kubernetes ファイナライザー(Finalizers)について学ぶ。
- ガベージコレクションについて学ぶ。
16 - データ暗号化にKMSプロバイダーを使用する
このページでは、機密データの暗号化を有効にするために、Key Management Service(KMS)プロバイダーとプラグインを設定する方法について説明します。 Kubernetes 1.34では、KMSによる保存時暗号化はv1とv2の2つのバージョンが利用できます。 KMS v1は(Kubernetes v1.28以降で)非推奨であり、(Kubernetes v1.29以降では)デフォルトで無効化されているため、特段の理由がない限りKMS v2を使用すべきです。 KMS v2は、KMS v1よりも大幅に優れたパフォーマンス特性を提供します。
注意:
このドキュメントは、KMS v2のGAな実装(および非推奨のv1の実装)について記載しています。 Kubernetes v1.29より古いコントロールプレーンコンポーネントを使用している場合は、クラスターが実行しているKubernetesのバージョンに対応するドキュメントの同等のページを確認してください。 以前のKubernetesのリリースでは、情報セキュリティに影響する可能性のある異なる挙動が存在します。始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
必要なKubernetesのバージョンは、選択したKMS APIバージョンによって異なります。 KubernetesではKMS v2の使用を推奨しています。
- バージョンv1.27より前のクラスターをサポートするためにKMS API v1を選択した場合、またはKMS v1のみをサポートするレガシーKMSプラグインを使用している場合、KMS v1をサポートする全てのKubernetesバージョンが動作します。 このAPIはKubernetes v1.28時点で非推奨です。 KubernetesではこのAPIの使用を推奨していません。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
KMS v1
Kubernetes v1.28 [deprecated]
-
Kubernetesバージョン1.10.0以降が必要です
-
バージョン1.29以降では、KMSのv1実装はデフォルトで無効になっています。 この機能を有効化するには、
--feature-gates=KMSv1=trueを設定してKMS v1プロバイダーを構成してください。 -
クラスターはetcd v3以降を使用する必要があります
KMS v2
Kubernetes v1.29 [stable]
- クラスターはetcd v3以降を使用する必要があります
KMS暗号化とオブジェクトごとの暗号化キー
KMSプロバイダーは、etcd内のデータを暗号化するためにエンベロープ暗号化方式を使用します。 データはデータ暗号化鍵(DEK)を使用して暗号化されます。 DEKは、リモートKMSで保存・管理される鍵暗号化鍵(KEK)で暗号化されます。
(非推奨の)KMSのv1実装を使用する場合、各暗号化に対して新しいDEKが生成されます。
KMS v2では、暗号化ごとに新しいDEKが生成されます: APIサーバーは 鍵導出関数 を使用して、シークレットシード(暗号鍵生成の種)とランダムデータを組み合わせて単一用途のデータ暗号化鍵を生成します。 シードは、KEKがローテーションされるたびにローテーションされます(詳細については、以下の「key_idと鍵ローテーションの理解」セクションを参照してください)。
KMSプロバイダーは、UNIXドメインソケット経由で特定のKMSプラグインと通信するためにgRPCを使用します。 KMSプラグインは、gRPCサーバーとして実装され、Kubernetesコントロールプレーンと同じホストにデプロイされ、リモートKMSとのすべての通信を担当します。
KMSプロバイダーの設定
APIサーバーでKMSプロバイダーを設定するには、暗号化設定ファイルのproviders配列にkmsタイプのプロバイダーを含め、以下のプロパティを設定してください:
KMS v1
apiVersion: KMSプロバイダーのAPIバージョン。 この値を空のままにするか、v1に設定してください。name: KMSプラグインの表示名。 一度設定すると変更できません。endpoint: gRPCサーバー(KMSプラグイン)のリッスンアドレス。 このエンドポイントはUNIXドメインソケットです。cachesize: 平文でキャッシュするデータ暗号化鍵(DEK)の数。 キャッシュする場合、DEKはKMSへの追加の呼び出しなしで使用できますが、キャッシュしない場合はKMSを呼び出して鍵を取り出す必要があります。timeout:kube-apiserverがエラーを返す前にkms-pluginの応答を待つ時間(デフォルトは3秒)。
KMS v2
apiVersion: KMSプロバイダーのAPIバージョン。 これをv2に設定してください。name: KMSプラグインの表示名。 一度設定すると変更できません。endpoint: gRPCサーバー(KMSプラグイン)のリッスンアドレス。 このエンドポイントはUNIXドメインソケットです。timeout:kube-apiserverがエラーを返す前にkms-pluginの応答を待つ時間(デフォルトは3秒)。
KMS v2はcachesizeプロパティをサポートしていません。
KMSを呼び出してサーバーが取り出した全てのデータ暗号化鍵(DEK)は、平文でキャッシュされます。
いったんキャッシュされたDEKは、KMSを呼び出すことなく無期限で復号に使用できます。
保存時暗号化設定の理解を参照してください。
KMSプラグインの実装
KMSプラグインを実装するには、新しいプラグインgRPCサーバーを開発するか、クラウドプロバイダーによって既に提供されているKMSプラグインを有効にすることができます。 その後、プラグインをリモートKMSと統合し、Kubernetesコントロールプレーンにデプロイします。
クラウドプロバイダーがサポートするKMSの有効化
クラウドプロバイダー固有のKMSプラグインを有効にする手順については、お使いのクラウドプロバイダーを参照してください。
KMSプラグインgRPCサーバーの開発
Go用に利用可能なスタブファイルを使用してKMSプラグインgRPCサーバーを開発できます。 他の言語については、protoファイルを使用してgRPCサーバーコードの開発に使用できるスタブファイルを作成します。
KMS v1
-
Goを使用する場合: gRPCサーバーコードを開発するには、スタブファイル内の関数とデータ構造を使用してください: api.pb.go
-
Go以外の言語を使用する場合: 個別言語向けのスタブファイルを生成するには、protocコンパイラーとprotoファイルを使用してください: api.proto
KMS v2
-
Goを使用する場合: gRPCサーバーコードの開発を簡単にするために高レベルライブラリが提供されています。 低レベルの実装では、スタブファイル内の関数とデータ構造を使用できます: api.pb.go
-
Go以外の言語を使用する場合: 個別言語向けのスタブファイルを生成するには、protocコンパイラーとprotoファイルを使用してください: api.proto
その後、スタブファイル内の関数とデータ構造を使用してサーバーコードを開発してください。
注意事項
KMS v1
-
KMSプラグインバージョン:
v1beta1Versionプロシージャコールへの応答で、互換性のあるKMSプラグインは
VersionResponse.versionとしてv1beta1を返す必要があります。 -
メッセージバージョン:
v1beta1KMSプロバイダーからのすべてのメッセージには、バージョンフィールドが
v1beta1に設定されています。 -
プロトコル: UNIXドメインソケット(
unix)プラグインは、UNIXドメインソケットでリッスンするgRPCサーバーとして実装されます。 稼働中のプラグインは、UNIXドメインソケットでgRPC接続を待受するために、ファイルシステム上にファイルを作成する必要があります。 APIサーバー(gRPCクライアント)は、KMSプロバイダー(gRPCサーバー)とUNIXドメインソケットを通じて通信するためにエンドポイントを設定します。
unix:///@fooのように、/@から始まるエンドポイントを指定すると、抽象化したLinuxソケットを利用できます。 従来のファイルベースのソケットとは異なり、このタイプのソケットにはACLの概念がないため、使用する際は注意が必要です。 ただし、これらのソケットはLinuxネットワーク名前空間で制御されるため、ホストネットワーキングが使用されていない限りは、同じPod内のコンテナからのみアクセスできます。
KMS v2
-
KMSプラグインバージョン:
v2Statusリモートプロシージャコールへの応答の際、KMS v2に互換なKMSプラグインはStatusResponse.versionとしてKMS互換性バージョンを返す必要があります。 また、ステータス応答にはStatusResponse.healthzとして「ok」、StatusResponse.key_idとしてkey_id(リモートKMSのKEK ID)を含める必要があります。 Kubernetesプロジェクトでは、プラグインを安定したv2KMS APIと互換性があるようにすることを推奨します。 Kubernetes 1.34はKMS用のv2beta1APIもサポートしており、将来のKubernetesリリースでもそのベータバージョンのサポートが継続される可能性があります。APIサーバーは、すべてが正常な場合は約1分ごとに
Statusプロシージャコールをポーリングし、プラグインが正常でない場合は10秒ごとにポーリングします。 プラグインは、常にこの呼び出し負荷がかかることを考慮して最適化する必要があります。 -
暗号化
EncryptRequestプロシージャコールは、平文に加えて、ログ目的のUIDフィールドを提供します。 応答には暗号文と使用するKEKのkey_idを含める必要があり、KMSプラグインが将来のDecryptRequest呼び出しを(annotationsフィールド経由で)支援するために必要とする、任意のメタデータを含めることもできます。 プラグインは、異なる任意の平文が異なる応答(ciphertext, key_id, annotations)を与えることを保証しなければなりません(MUST)。プラグインが空でない
annotationsマップを返す場合、すべてのマップキーはexample.comのような完全修飾ドメイン名である必要があります。annotationの使用例は{"kms.example.io/remote-kms-auditid":"<audit ID used by the remote KMS>"}です。APIサーバーは高頻度で
EncryptRequestプロシージャコールを実行しませんが、プラグインの実装では各リクエストのレイテンシーを100ミリ秒未満に保つことを目指す必要があります。 -
復号
DecryptRequestプロシージャコールでは、EncryptRequestから得た(ciphertext, key_id, annotations)とログ目的のUIDを提供します。 期待される通り、これはEncryptRequest呼び出しの逆です。 プラグインはkey_idが既知のものかどうかを検証しなければなりません(MUST)。 また、以前にプラグイン自身が暗号化したデータであることを確証できない限り、データの復号を試みてはいけません(MUST NOT)。APIサーバーは、Watchキャッシュを満たすために起動時に何千もの
DecryptRequestプロシージャコールを実行する可能性があります。 したがって、プラグインの実装はこれらの呼び出しを可能な限り迅速に実行する必要があり、各リクエストのレイテンシーを10ミリ秒未満に保つことを目指す必要があります。 -
key_idと鍵ローテーションの理解key_idは、現在使用中のリモートKMS KEKの公開された非機密の名前です。 APIサーバーの通常の動作中にログに記録される可能性があるため、プライベートデータを含んではいけません。 プラグインの実装では、データの漏洩を避けるためにハッシュの使用が推奨されます。 KMS v2メトリクスは、/metricsエンドポイント経由で公開する前にこの値をハッシュ化するよう注意しています。APIサーバーは、
Statusプロシージャコールから返されるkey_idを信頼できるものと見なします。 したがって、この値の変更は、リモートKEKが変更されたことをAPIサーバーに通知し、古いKEKで暗号化されたデータはno-op書き込みが実行されたときに古いものとしてマークされる必要があります(以下で説明)。EncryptRequestプロシージャコールがStatusとは異なるkey_idを返す場合、応答は破棄され、プラグインは正常でないと見なされます。 したがって、実装はStatusから返されるkey_idがEncryptRequestによって返されるものと同じであることを保証する必要があります。 さらに、プラグインはkey_idが安定しており、値間で変動しないことを確保する必要があります(つまり、リモートKEKローテーション中)。プラグインは、以前に使用されたリモートKEKが復元された状況でも、
key_idを再利用してはいけません。 プラグインがkey_id=Aを使用していて、key_id=Bに切り替え、その後key_id=Aに戻った場合、key_id=Aを報告する代わりに、プラグインはkey_id=A_001のような派生値を報告するか、key_id=Cのような新しい値を使用する必要があります。APIサーバーは約1分ごとに
Statusをポーリングするため、key_idローテーションは即座には行われません。 さらに、APIサーバーは約3分間最後の有効な状態で継続します。 したがって、ユーザーがストレージ移行に対して受動的な(つまり、待機による)アプローチを取りたい場合、リモートKEKがローテーションされた後の3 + N + M分でマイグレーションを予定する必要があります(Nはプラグインがkey_idの変更を検知するのにかかる時間、Mは設定変更が処理されることを許可するための望ましいバッファです。Mの最小値は5分が推奨されます)。 KEKローテーションを実行するためにAPIサーバーの再起動は必要ないことに注意してください。注意:
DEKで実行される書き込み数を制御できないため、Kubernetesプロジェクトでは、KEKを少なくとも90日ごとにローテーションすることを推奨します。 -
プロトコル: UNIXドメインソケット(
unix)プラグインは、UNIXドメインソケットでリッスンするgRPCサーバーとして実装されます。 稼働中のプラグインは、UNIXドメインソケットでgRPC接続を待受するために、ファイルシステム上にファイルを作成する必要があります。 APIサーバー(gRPCクライアント)は、KMSプロバイダー(gRPCサーバー)とUNIXドメインソケットを通じて通信するためにエンドポイントを設定します。
unix:///@fooのように、/@から始まるエンドポイントを指定すると、抽象化したLinuxソケットを利用できます。 従来のファイルベースのソケットとは異なり、このタイプのソケットにはACLの概念がないため、使用する際は注意が必要です。 ただし、これらのソケットはLinuxネットワーク名前空間で制御されるため、ホストネットワーキングが使用されていない限りは、同じPod内のコンテナからのみアクセスできます。
KMSプラグインとリモートKMSの統合
KMSプラグインは、KMSがサポートする任意のプロトコルを使用してリモートKMSと通信できます。
KMSプラグインがリモートKMSとの通信に使用する認証資格情報を含むすべての設定データは、KMSプラグインによって独立して保存・管理されます。
KMSプラグインは、復号のためにKMSに送信する前に必要な追加のメタデータで暗号文をエンコードできます(KMS v2は専用のannotationsフィールドを提供することでこのプロセスを簡単にします)。
KMSプラグインのデプロイ
KMSプラグインがKubernetes APIサーバーと同じホストで実行されることを確認してください。
KMSプロバイダーでデータを暗号化する
データを暗号化するには:
-
SecretやConfigMapなどのリソースを暗号化するために、
kmsプロバイダーの適切なプロパティを使用して新しいEncryptionConfigurationファイルを作成します。 CustomResourceDefinitionで定義された拡張APIを暗号化したい場合、クラスターはKubernetes v1.26以降を実行している必要があります。 -
kube-apiserverの
--encryption-provider-configフラグを、設定ファイルの場所を指すように設定します。 -
--encryption-provider-config-automatic-reloadブール引数は、--encryption-provider-configで設定されたファイルがディスクの内容が変更された場合に自動的にリロードされるかどうかを決定します。 -
APIサーバーを再起動します。
KMS v1
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile-foo.sock
cachesize: 100
timeout: 3s
- kms:
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile-bar.sock
cachesize: 100
timeout: 3s
KMS v2
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
apiVersion: v2
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile-foo.sock
timeout: 3s
- kms:
apiVersion: v2
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile-bar.sock
timeout: 3s
--encryption-provider-config-automatic-reloadをtrueに設定すると、すべてのヘルスチェックが単一のヘルスチェックエンドポイントに統合されます。
個別のヘルスチェックは、KMS v1プロバイダーが使用されており、暗号化設定が自動リロードされない場合にのみ利用できます。
以下の表は、各KMSバージョンのヘルスチェックエンドポイントをまとめています:
| KMS設定 | 自動リロードなし | 自動リロードあり |
|---|---|---|
| KMS v1のみ | 個別ヘルスチェック | 単一ヘルスチェック |
| KMS v2のみ | 単一ヘルスチェック | 単一ヘルスチェック |
| KMS v1とv2の両方 | 個別ヘルスチェック | 単一ヘルスチェック |
| KMSなし | なし | 単一ヘルスチェック |
単一ヘルスチェックは、唯一のヘルスチェックエンドポイントが/healthz/kms-providersであることを意味します。
個別ヘルスチェックは、各KMSプラグインが暗号化設定での位置に基づいて関連するヘルスチェックエンドポイントを持つことを意味します: /healthz/kms-provider-0、/healthz/kms-provider-1など。
これらのヘルスチェックエンドポイントパスはハードコードされており、サーバーによって生成/制御されます。 個別ヘルスチェックのインデックスは、KMS暗号化設定が処理される順序に対応します。
すべてのシークレットが暗号化されていることを確認するで定義された手順が実行されるまで、providersリストは暗号化されていないデータの読み取りを許可するためにidentity: {}プロバイダーで終わる必要があります。
すべてのリソースが暗号化されたら、APIサーバーが暗号化されていないデータを受け入れることを防ぐためにidentityプロバイダーを削除する必要があります。
EncryptionConfiguration形式の詳細については、APIサーバー暗号化APIリファレンスを確認してください。
データが暗号化されていることを確認する
保存時暗号化が正しく設定されている場合、リソースは書き込み時に暗号化されます。
kube-apiserverを再起動した後、新しく作成または更新されたSecretやEncryptionConfigurationで設定されたその他のリソースタイプは、保存時に暗号化される必要があります。
確認するには、etcdctlコマンドラインプログラムを使用して機密データの内容を取得できます。
-
default名前空間にsecret1という新しいシークレットを作成します:kubectl create secret generic secret1 -n default --from-literal=mykey=mydata -
etcdctlコマンドラインを使用して、etcdからそのシークレットを読み取ります:ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 [...] | hexdump -Cここで
[...]にはetcdサーバーに接続するための追加の引数が含まれます。 -
保存されたシークレットがKMS v1の場合は
k8s:enc:kms:v1:で始まり、KMS v2の場合はk8s:enc:kms:v2:で始まることを確認します。 これはkmsプロバイダーが結果データを暗号化したことを示します。 -
API経由で取得されたときに、シークレットが正しく復号されることを確認します:
kubectl describe secret secret1 -n defaultSecretには
mykey: mydataが含まれている必要があります
すべてのシークレットが暗号化されていることを確認する
保存時暗号化が正しく設定されている場合、リソースは書き込み時に暗号化されます。 したがって、データが暗号化されることを確保するために、インプレースでno-op更新を実行できます。
以下のコマンドは、すべてのシークレットを読み取り、その後サーバーサイド暗号化を適用するために更新します。 競合する書き込みによるエラーが発生した場合は、コマンドを再試行してください。 大規模なクラスターの場合、名前空間によってシークレットを細分化するか、更新をスクリプト化することをお勧めします。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
ローカル暗号化プロバイダーからKMSプロバイダーへの切り替え
ローカル暗号化プロバイダーからkmsプロバイダーに切り替えて、すべてのシークレットを再暗号化するには:
-
以下の例に示すように、
kmsプロバイダーを設定ファイルの最初のエントリとして追加します。apiVersion: apiserver.config.k8s.io/v1 kind: EncryptionConfiguration resources: - resources: - secrets providers: - kms: apiVersion: v2 name : myKmsPlugin endpoint: unix:///tmp/socketfile.sock - aescbc: keys: - name: key1 secret: <BASE64エンコード済みシークレット> -
すべての
kube-apiserverプロセスを再起動します。 -
以下のコマンドを実行して、
kmsプロバイダーを使用してすべてのシークレットを強制的に再暗号化します。kubectl get secrets --all-namespaces -o json | kubectl replace -f -
次の項目
Kubernetes APIに永続化されたデータの暗号化をもう使用したくない場合は、既に保存時に保存されているデータの復号を読んでください。
17 - サービスディスカバリーにCoreDNSを使用する
このページでは、CoreDNSのアップグレードプロセスと、kube-dnsの代わりにCoreDNSをインストールする方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9.バージョンを確認するには次のコマンドを実行してください: kubectl version.
CoreDNSについて
CoreDNSは、KubernetesクラスターDNSとして稼働させることができる柔軟で拡張可能なDNSサーバーです。Kubernetesと同様に、CoreDNSプロジェクトはCNCFによってホストされています。
既存のデプロイでkube-dnsを置き換えるか、クラスターのデプロイとアップグレードを代行してくれるkubeadmのようなツールを使用することで、クラスターでkube-dnsの代わりにCoreDNSを使用することができます。
CoreDNSのインストール
kube-dnsの手動デプロイや置き換えについては、CoreDNS websiteのドキュメントを参照してください。
CoreDNSへの移行
kubeadmを使用した既存のクラスターのアップグレード
Kubernetesバージョン1.21でkubeadmはDNSアプリケーションとしてのkube-dnsに対するサポートを削除しました。
kubeadm v1.34に対してサポートされるクラスターDNSアプリケーションはCoreDNSのみです。
kube-dnsを使用しているクラスターをkubeadmを使用してアップグレードするときに、CoreDNSに移行することができます。
この場合、kubeadmは、kube-dns ConfigMapをベースにしてCoreDNS設定("Corefile")を生成し、スタブドメインおよび上流のネームサーバーの設定を保持します。
CoreDNSのアップグレード
KubernetesのバージョンごとにkubeadmがインストールするCoreDNSのバージョンは、KubernetesにおけるCoreDNSのバージョンのページで確認することができます。
CoreDNSのみをアップグレードしたい場合や、独自のカスタムイメージを使用したい場合は、CoreDNSを手動でアップグレードすることができます。
スムーズなアップグレードのために役立つガイドラインとウォークスルーが用意されています。
クラスターをアップグレードする際には、既存のCoreDNS設定("Corefile")が保持されていることを確認してください。
kubeadmツールを使用してクラスターをアップグレードしている場合、kubeadmは既存のCoreDNSの設定を自動的に保持する処理を行うことができます。
CoreDNSのチューニング
リソース使用率が問題になる場合は、CoreDNSの設定を調整すると役立つ場合があります。 詳細は、CoreDNSのスケーリングに関するドキュメントを参照してください。
次の項目
CoreDNSは、設定("Corefile")を変更することで、kube-dnsよりも多くのユースケースをサポートする構成にすることができます。
詳細はKubernetes CoreDNSプラグインのドキュメントを参照するか、CoreDNSブログを参照してください。
18 - KubernetesクラスターでNodeLocal DNSキャッシュを使用する
Kubernetes v1.18 [stable]
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
イントロダクション
NodeLocal DNSキャッシュは、クラスターノード上でDNSキャッシュエージェントをDaemonSetで稼働させることで、クラスターのDNSパフォーマンスを向上させます。現在のアーキテクチャにおいて、ClusterFirstのDNSモードでのPodは、DNSクエリー用にkube-dnsのService IPに疎通します。これにより、kube-proxyによって追加されたiptablesを介してkube-dns/CoreDNSのエンドポイントへ変換されます。この新しいアーキテクチャによって、Podは同じノード上で稼働するDNSキャッシュエージェントに対して疎通し、それによってiptablesのDNATルールとコネクショントラッキングを回避します。ローカルのキャッシュエージェントはクラスターのホスト名(デフォルトではcluster.localというサフィックス)に対するキャッシュミスがあるときはkube-dnsサービスへ問い合わせます。
動機
-
現在のDNSアーキテクチャでは、ローカルのkube-dns/CoreDNSがないとき、DNSへの秒間クエリー数が最も高いPodは他のノードへ疎通する可能性があります。ローカルでキャッシュを持つことにより、この状況におけるレイテンシーの改善に役立ちます。
-
iptables DNATとコネクショントラッキングをスキップすることはconntrackの競合を減らし、UDPでのDNSエントリーがconntrackテーブルを満杯にすることを避けるのに役立ちます。
-
ローカルのキャッシュエージェントからkube-dnsサービスへの接続がTCPにアップグレードされます。タイムアウトをしなくてはならないUDPエントリーと比べ、TCPのconntrackエントリーはコネクションクローズ時に削除されます(デフォルトの
nf_conntrack_udp_timeoutは30秒です)。 -
DNSクエリーをUDPからTCPにアップグレードすることで、UDPパケットの欠損や、通常30秒(10秒のタイムアウトで3回再試行する)であるDNSのタイムアウトによるテイルレイテンシーを減少させます。NodeLocalキャッシュはUDPのDNSクエリーを待ち受けるため、アプリケーションを変更する必要はありません。
-
DNSクエリーに対するノードレベルのメトリクスと可視性を得られます。
-
DNSの不在応答のキャッシュも再度有効にされ、それによりkube-dnsサービスに対するクエリー数を減らします。
アーキテクチャ図
この図はNodeLocal DNSキャッシュが有効にされた後にDNSクエリーがあったときの流れとなります。

Nodelocal DNSCacheのフロー
この図は、NodeLocal DNSキャッシュがDNSクエリーをどう扱うかを表したものです。
設定
備考:
NodeLocal DNSキャッシュのローカルリッスン用のIPアドレスは、クラスター内の既存のIPと衝突しないことが保証できるものであれば、どのようなアドレスでもかまいません。例えば、IPv4のリンクローカル範囲169.254.0.0/16やIPv6のユニークローカルアドレス範囲fd00::/8から、ローカルスコープのアドレスを使用することが推奨されています。この機能は、下記の手順により有効化できます。
-
nodelocaldns.yamlと同様のマニフェストを用意し、nodelocaldns.yamlという名前で保存してください。 -
マニフェスト内の変数を正しい値に置き換えてください。
-
kubedns=
kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP} -
domain=
<cluster-domain> -
localdns=
<node-local-address>
<cluster-domain>はデフォルトで"cluster.local"です。<node-local-address>はNodeLocal DNSキャッシュ用に確保されたローカルの待ち受けIPアドレスです。-
kube-proxyがIPTABLESモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml__PILLAR__CLUSTER__DNS__と__PILLAR__UPSTREAM__SERVERS__はnode-local-dnsというPodによって生成されます。 このモードでは、node-local-dns Podは<node-local-address>とkube-dnsのサービスIPの両方で待ち受けるため、PodはIPアドレスでもDNSレコードのルップアップができます。 -
kube-proxyがIPVSモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yamlこのモードでは、node-local-dns Podは
<node-local-address>上のみで待ち受けます。node-local-dnsのインターフェースはkube-dnsのクラスターIPをバインドしません。なぜならばIPVSロードバランシング用に使われているインターフェースは既にこのアドレスを使用しているためです。__PILLAR__UPSTREAM__SERVERS__はnode-local-dns Podにより生成されます。
-
-
kubectl create -f nodelocaldns.yamlを実行してください。 -
kube-proxyをIPVSモードで使用しているとき、NodeLocal DNSキャッシュが待ち受けている
<node-local-address>を使用するため、kubeletに対する--cluster-dnsフラグを修正する必要があります。IPVSモード以外のとき、--cluster-dnsフラグの値を修正する必要はありません。なぜならNodeLocal DNSキャッシュはkube-dnsのサービスIPと<node-local-address>の両方で待ち受けているためです。
一度有効にすると、クラスターの各Node上で、kube-systemという名前空間でnode-local-dns Podが、稼働します。このPodはCoreDNSをキャッシュモードで稼働させるため、異なるプラグインによって公開された全てのCoreDNSのメトリクスがNode単位で利用可能となります。
kubectl delete -f <manifest>を実行してDaemonSetを削除することによって、この機能を無効にできます。また、kubeletの設定に対して行った全ての変更をリバートすべきです。
19 - EndpointSliceの有効化
このページはKubernetesのEndpointSliceの有効化の概要を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
概要
EndpointSliceは、KubernetesのEndpointsに対してスケーラブルで拡張可能な代替手段を提供します。Endpointsが提供する機能のベースの上に構築し、スケーラブルな方法で拡張します。Serviceが多数(100以上)のネットワークエンドポイントを持つ場合、それらは単一の大きなEndpointsリソースではなく、複数の小さなEndpointSliceに分割されます。
EndpointSliceの有効化
Kubernetes v1.17 [beta]
備考:
EndpointSliceは、最終的には既存のEndpointsを置き換える可能性がありますが、多くのKubernetesコンポーネントはまだ既存のEndpointsに依存しています。現時点ではEndpointSliceを有効化することは、Endpointsの置き換えではなく、クラスター内のEndpointsへの追加とみなされる必要があります。EndpoitSliceはベータ版の機能です。APIとEndpointSliceコントローラーはデフォルトで有効です。kube-proxyはデフォルトでEndpointSliceではなくEndpointsを使用します。
スケーラビリティと性能向上のため、kube-proxy上でEndpointSliceProxyingフィーチャーゲートを有効にできます。この変更はデータソースをEndpointSliceに移します、これはkube-proxyとKubernetes API間のトラフィックの量を削減します。
EndpointSliceの使用
クラスター内でEndpointSliceを完全に有効にすると、各Endpointsリソースに対応するEndpointSliceリソースが表示されます。既存のEndpointsの機能をサポートすることに加えて、EndpointSliceはトポロジーなどの新しい情報を含みます。これらにより、クラスター内のネットワークエンドポイントのスケーラビリティと拡張性が大きく向上します。
次の項目
- EndpointSliceを参照してください。
- サービスとアプリケーションの接続を参照してください。